Plan wykładów¶
- tekst jako łańcuch znaków
- tekst jako zbiór zjawisk językowych
- zastosowania metod przetwarzaniu tekstu
- modele analizy tekstu
- narzędzia do analizy tekstu
- zasoby tekstowe
Tekst jako łańcuch znaków¶
Problem: zliczenie wystąpień wyrazu w tekście¶
Ile razy w bazie danych w tabeli words w kolumnie value występuje wyraz wirus?
Ile razy w tekście występuje wyraz wirus?
a = 1.00001
if(a == 1):
print("Zmienna ma wartość 1")
if(abs(a - 1) < 1e-3):
print("Zmienna ma wartość zbliżoną do 1")
- czy uwzględniamy pisownię wielką i małą literą?
np. Ruby v. 1.9.3 (i wiele późniejszych wersji)
1.9.3-p551 :001 > "Ł".downcase
=> "Ł"
1.9.3-p551 :002 >Ruby 2.7.0
2.7.0 :001 > "Ł".downcase
=> "ł"
2.7.0 :002 >- czy uwzględniamy fleksję? - wirus, wirusa, wirusowi, wirusem
Przykłady wieloznaczności morfologicznej
- przyglądam się wirusowi
- pacjenci wirusowi
from morfeusz2 import Morfeusz
import pandas as pd
morf = Morfeusz()
forms = morf.generate("wirus")
pd.DataFrame(forms, columns=['inflected form', 'base form', 'tags', 'categories', 'misc'])
- czy uwzględniamy słowotwórstwo i relacje morfologiczne? - wirus/wirusowe, lekarz/leczenie
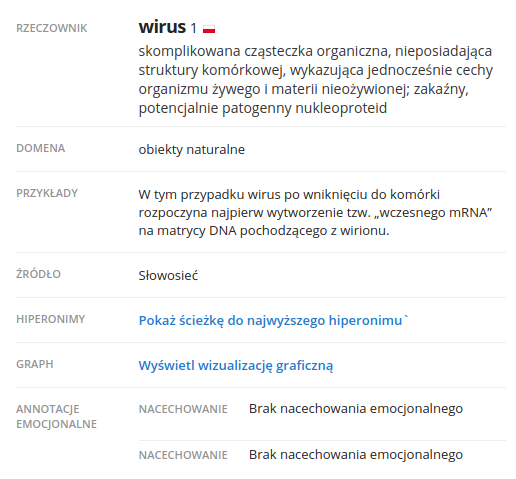
skąd pochodzą teksty?
Aa
- A a
Zliczanie wystąpień wyrażenia w tekście¶
Ile razy w tekście występuje wyrażenie wirusowe zapalenie wątroby?
- czy wszystkie wyrazy są odmienne?
- czy pomiędzy wyrazami mogą występować inne wyraz nie należące do wyrażenia?
- czy spacja jest zawsze tym czym nam się wydaje, że jest?
- czy uwzględniamy skróty? (WZW)
- czy uwzględniamy synonimy? (żółtaczka)
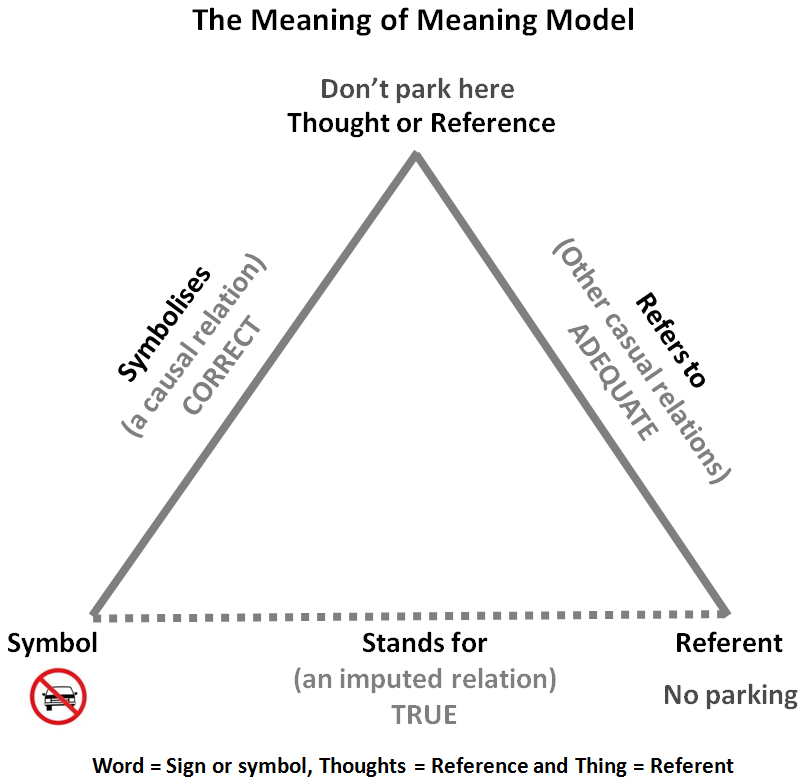
Trójkąt semiotyczny Ogdena-Richardsa¶
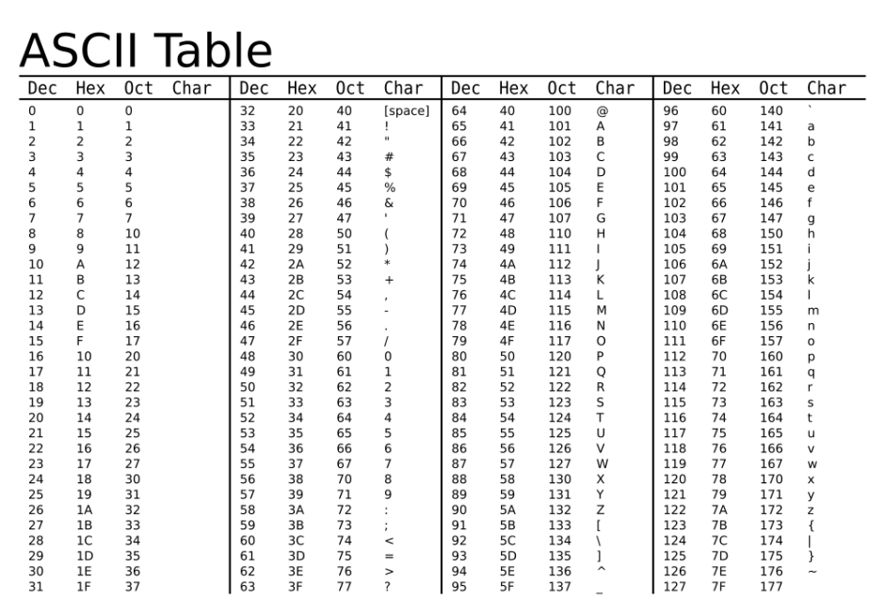
Problem kodowania znaków¶
Popularne rodzaje kodowania znaków (z uwzględnieniem języka polskiego):
- ASCII
- iso-8859-2 (Unix)
- code page 1250 (Windows)
- Unicode: UTF-8, UTF-16 (Windows, Unix, Web)
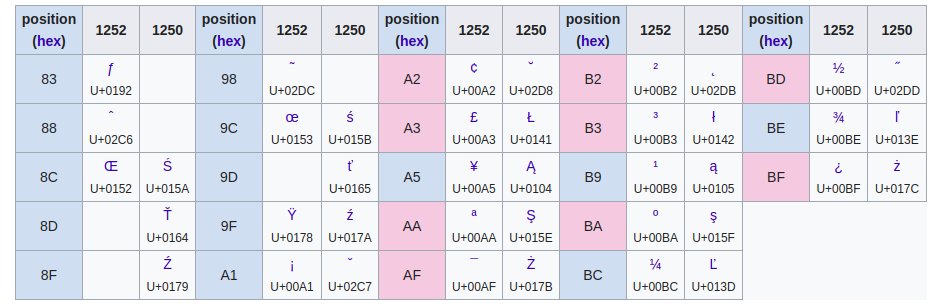
ISO-8859-2 vs. CP1250 (1 bajtowe kodowanie)¶
ISO-8859-2¶
- Albanian, Bosnian, Croatian, Czech, , German, Hungarian, Polish, Serbian, Slovak, Slovene, Upper Sorbian, Lower Sorbian, Turkmen
CP1250¶
- Albanian, Bosnian, Croatian, Czech, German, Hungarian, Polish, Serbian, Slovak, Slovene, Romanian
!cat iso-8859-2.txt
import codecs
with codecs.open("iso-8859-2.txt", 'r', 'iso-8859-2') as f:
for line in f:
print(line)
Unicode + UTF-8, UTF-16, UTF-32¶
Unikod (ang. Unicode) – komputerowy zestaw znaków mający w zamierzeniu obejmować wszystkie pisma używane na świecie.
UTF-8 (ang. 8-bit Unicode Transformation Format) – system kodowania Unicode, wykorzystujący od 1 do 4 bajtów do zakodowania pojedynczego znaku, w pełni kompatybilny z ASCII.
UTF-16 (ang. 16-bit Unicode Transformation Format) – jeden ze sposobów kodowania znaków standardu Unicode (2 lub 4 bajty, <= U+10000 kodowane na 2 bajtach).
UTF-32 (ang. 32-bit unicode transformation format) – jeden ze sposobów kodowania znaków standardu Unicode (zawsze 4 bajty).
(Źródło: Wikipedia)
Unicode¶
| Wersja | Data | Publikacja | Oznaczenie | Liczba zestawów znaków | Liczba znaków | Liczba nowych znaków |
|---|---|---|---|---|---|---|
| 13.0 | March 2020 | ISBN 978-1-936213-26-9 | ISO/IEC 10646:2020[51] | 154 | 143,859 | 5,930 added) |
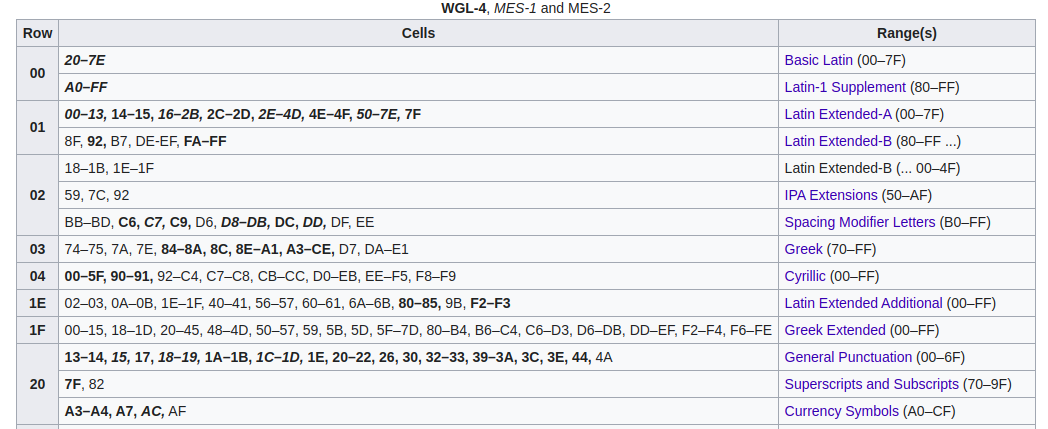
Latin Extended-A¶
from unidecode import unidecode
print(unidecode("Kaplica Sykstyńska"))
print(unidecode("Сикстинская капелла")) # cyrylica
print(unidecode("Καπέλα Σιστίνα")) # grecki
print(unidecode("西斯汀小堂")) # chiński
print(unidecode("Սիքստինյան կապելլա")) # ormiański
Kaplica Sykstynska Sikstinskaia kapella Kapela Sistina Xi Si Ting Xiao Tang Sik`stinyan kapella
import demoji
#demoji.download_codes()
demoji.findall("""
#startspreadingthenews yankees win great start by 🎅🏾 going 5strong innings with 5k’s🔥 🐂 solo homerun 🌋🌋
with 2 solo homeruns and👹 3run homerun… 🤡 🚣🏼 👨🏽⚖️ with rbi’s … 🔥🔥
🇲🇽 and 🇳🇮 to close the game🔥🔥!!!….
WHAT A GAME!!..
""")
UTF-8¶
Zalety¶
- Każdy tekst w ASCII jest tekstem w UTF-8.
- Żaden znak spoza ASCII nie zawiera bajtu z ASCII.
- Zachowuje porządek sortowania UCS-4.
- Typowy tekst ISO-Latin-X rozrasta się w bardzo niewielkim stopniu po przekonwertowaniu do UTF-8.
- Nie zawiera bajtów 0xFF i 0xFE, więc łatwo można go odróżnić od tekstu UTF-16.
- Znaki o kodzie różnym od 0 nie zawierają bajtu 0, co pozwala stosować UTF-8 w ciągach zakończonych zerem.
- O każdym bajcie wiadomo, czy jest początkiem znaku, czy też leży w jego środku, co nie jest dostępne np. w kodowaniu EUC.
- Nie ma problemów z little endian vs big endian.
- Jest domyślnym kodowaniem w XML (również w jego aplikacjach: XHTML, SVG, XSL, CML, MathML).
Odległość edycyjna łańcuchów znaków¶
Minimalna liczba operacji:
- usunięcia
- dodania
- zamiany
pojedynczego znaku, dzięki którym łańcych S1 może zostać przekształcony w łańcuch S2.
|
|
Implementacje¶
- algorytm dynamiczny - do porównywania pojedynczych łańcuchów znaków
- algorytm korekty tekstu Norviga - odwrócenie problemu https://norvig.com/spell-correct.html
- Levenshtein automaton - znacznie szybszy niż algorytm Norviga, zaimplementowany np. w ElasticSearch
Przykładowe zastosowania miary edycyjnej¶
- wyszukiwanie przybliżone (fuzzy search - did you mean?)
- automatyczna korekta tekstu
- interpretacja komend głosowych
Narzędzia¶
- Fuzzywuzzy - https://github.com/seatgeek/fuzzywuzzy
- ElasticSearch - fuzzy match https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html
- Algorytm Norviga - https://norvig.com/spell-correct.html
- Language tool - https://www.languagetool.org/
- biblioteka regex - https://pypi.org/project/regex/
import re
pattern = re.compile('wirus')
texts = ["wrius", "wirrus", "wirs"]
for text in texts:
match_data = pattern.search(text)
if(match_data):
print(match_data[0])
import regex
pattern = regex.compile(r'(wirus\b){e<=1}')
texts = ["virus", "wirrus", "wirusa"]
for text in texts:
match_data = pattern.search(text)
if(match_data):
print(match_data[0])
virus wirrus wirusa
Wyrażenia regularne¶
- pozwalają na konstrukcję wzorców dopasowujących się do tekstu
- pozwalają na uwzględnienie wariantów w pisowni
- w ograniczonym stopniu pozwalają na uwzględnienie błędów w pisowni
- w ograniczonym stopniu pozwalają na uwzględnienie fleksji
- wiele realnie działających systemów przetwarzających tekst opiera się w dużej mierze na wyrażeniach regularnych
import re
pattern = re.compile('łódź', re.I)
text = "Łódź to stolica województwa łódzkiego"
if(pattern.search(text)):
print("Wyrażenie zostało dopasowane")
Wyrażenie zostało dopasowane
tab = ["Poznań", "Łódź", "Andrychów"]
sorted(tab)
['Andrychów', 'Poznań', 'Łódź']
pattern = re.compile(r'\bwirus(\w*)',)
texts = ["a _wirusów", "wirusowe zapalenie wątroby", "wirusy są groźne", "koronawirus"]
for text in texts:
match_data = pattern.search(text)
if(match_data):
print(match_data[0])
wirusowe wirusy
Wyrażenia regularne¶
- Podstawowe metaznaki:
*– (kwantyfikator) zero lub więcej wystąpień()– grupowanie wyrażeń dla kwantyfikatorów, alternatywy, dopasowań wstecznych|– alternatywa – jedna opcja spośród wielu
- Kwantyfikatory (określają ile razy ma być dopasowane wyrażenie, które stoi przed nimi):
*– zero lub więcej wystąpień (to samo co wyżej)+– jedno lub więcej wystąpień?– zero lub jedno wystąpienie
- Kotwice (dopasowują się do pozycji w łańcuchu, a nie konkretnych znaków):
^– początek linii$– koniec linii\b– granica słowa\<– początek słowa\>– koniec słowa
- Klasy znaków:
[]– jeden ze znaków znajdujących się wewnątrz nawiasów^– pojawiając się na początku w kontekście klasy znaków powoduje jej zanegowaniea-z– zakres znaków (tylko wew. nawiasów kwadratowych)\w– znak będący literą, cyfrą lub podkreśleniem\s– znak będący białą spacją (spacja, tabulator, koniec linii, etc.)\d– cyfra.– dowolny znak (zazwyczaj – niebędący końcem linii)
Zaawansowane własności wyrażeń regularny¶
- Wsparcie dla Unicode:
- https://www.regular-expressions.info/unicode.html
\p{L}- litery z dowolnego alfabetu (np. a, ą, ć, ü, カ)\p{Ll}- mała litera z dowolnego alfabetu\p{Lu}- wielka litera z dowolnego alfabetu\X- dowonly znak Unicode (jak.ale automatycznie uwzględnia znaki przejścia do nowej linii)
- positive lookahead
- wyrażenie
(\w+)(?= ma kota)dopasuje się do łańcucha Ala ma kota, ale dopasowanie obejmie tylko słowo Ala.
- wyrażenie
- negative lookbehind
- wyrażenie
(?<!starych )(zł)dopasuje się do łańcucha 10 złotych ale nie do łańcucha 10 starych złotych.
- wyrażenie
import re
text = "aaa"
print(re.findall("aa", text))
print(re.findall("a(?=a)", text))
['aa'] ['a', 'a']
text1 = "New York"
text2 = "Yorkshire"
print(re.findall("(?<!New )York", text1))
print(re.findall("(?<!New )York", text2))
[] ['York']
Narzędzia¶
- Python
re- standardowa biblioteka - https://docs.python.org/3/library/re.htmlpip install regex- biblioteka instalowana osobno - https://pypi.org/project/regex/
- Java
- java.util.regex.Pattern - https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html
- Ruby - https://ruby-doc.org/core-2.5.1/Regexp.html
- literał
/a.*/
- literał
- Javascript - https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions
- literał
/a.*/
- literał
