

(ang. lock)



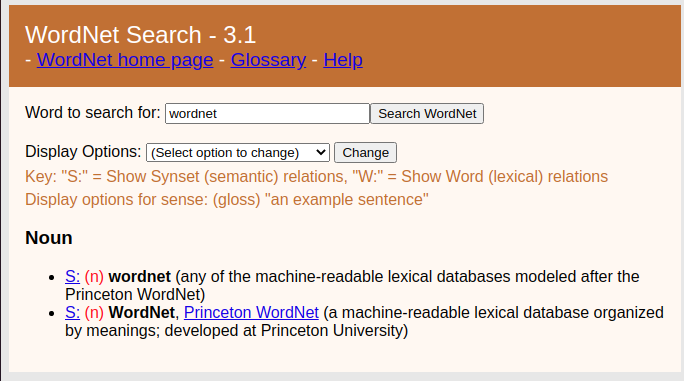
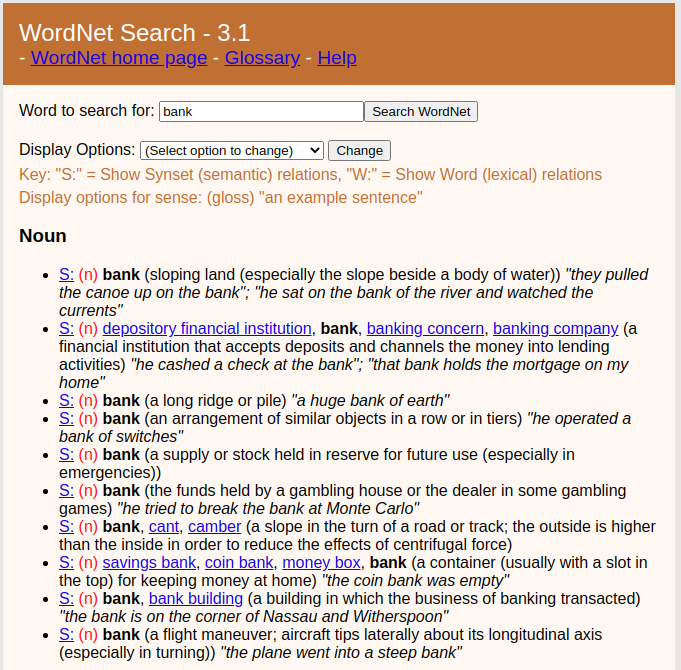
WordNet¶
- prace rozpoczęto w 1985 na Uniwersytecie w Princeton
- pierwszy WordNet powstał dla języka angielskiego
- obecnie istnieje szereg WordNetów (w tym 2 dla j. polskiego), twórcy są zrzeszeni w ramach Global WordNet Association
- na początku XXI wieku WordNet stanowił podstawowy zasób służący do reprezentacji sensu


Synonimia¶
zastępowalność w tym samym kontekście
- Widziałem jak jakiś gliniarz pałował demonstrantów.
- Widziałem jak jakiś pies pałował demonstrantów.
wzajemność relacji "bycia rodzajem"
- pies jest rodzajem gliniarza
- gliniarz jest rodzajem psa
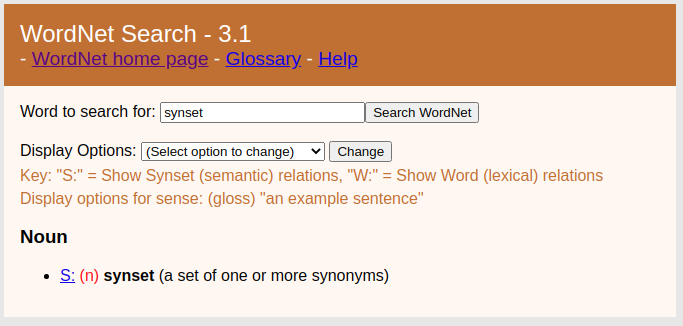
Synset - definicja w Słowosieci¶
We put a given LU (=linguistic unit) into a synset because of all lexico-semantic relations of this LU with other units in the network
A WordNet from the Groud Up, Maciej Piasecki, Stanisław Szpakowicz, Bartosz Broda, 2009
Relacje semantyczne w Słowosieci¶
- synonimia
- hiperonimia/hiponimia
- holonimia/meronimia
- anotnimia
- konwersja
- holonimia/meronimia czasownikowa
- bliskoznaczność
- ...
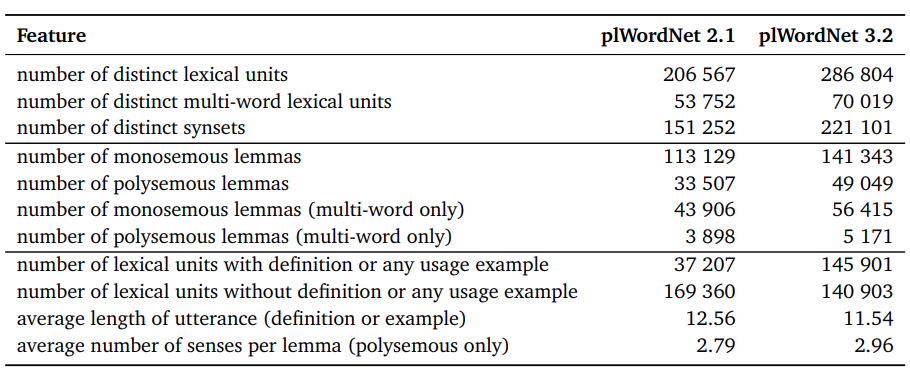
Aktualnie w Słowosieci wyróżnia się 41 relacji (oraz wiele podtypów relacji głównych).
Tabela najważniejszych relacji¶
| relacja | test | klasy syntaktyczne | przykład |
|---|---|---|---|
| hiponimia/ hiperonimia |
X ma węższe znaczenie, niż Y |
N-N, Adj-Adj, Adv-Adv, V-V |
jabłko $\rightarrow$ owoc |
| meronimia/ holonimia |
X jest częścią Y | N-N | szprycha $\rightarrow$ koło |
| antonimia | X i Y mają przeciwne znaczenia |
N-N, Adj-Adj, Adv-Adv, V-V |
martwy $\leftrightarrow$ żywy |
| konwersja | X i Y w układzie odniesienia są tym samym, ale postrzeganym z różnych punktów widzenia |
N-N, Adj-Adj, Adv-Adv, V-V |
mąż $\leftrightarrow$ żona |
| meronimia/ holonimia czasownikowa |
X towarszyszy Y | V-V | chrapać $\rightarrow$ spać |
http://www.nlp.pwr.wroc.pl/2-uncategorised/81-relacje-w-slowosieci
- Jabłoń jest rodzajem drzewa
- Drzewo jest rodzajem rośliny
- $\rightarrow$ Jabłoń jest rodzajem rośliny
- Anna jest (rodzajem) programistką
- Programistka jest rodzajem zawodu
- $\nrightarrow$ Anna jest (rodzajem) zawodem
Ujęcie teoriomnogościowe¶
- odróżnienie należenia do zbioru $\in$ od zawierania zbiorów $\subset$.
- $\textrm{JABŁOŃ} \subset \textrm{DRZEWO} \hspace{2cm} \forall x : \textrm{JABŁOŃ}(x) \rightarrow \textrm{DRZEWO}(X)$
- $\textrm{DRZEWO} \subset \textrm{ROŚLINA}$
- $\textrm{JABŁOŃ} \subset \textrm{ROŚLINA}$
- $\textrm{ANNA} \in \textrm{PROGRAMISTKA}$
- $\textrm{PROGRAMISTKA} \in \textrm{ZAWÓD}$
- $\textrm{ANNA} \notin \textrm{ZAWÓD}$

Test zastępowalności¶
- Na placu stoi jakaś jabłoń
- Na placu stoi jakieś drzewo
- Na placu stoi jakaś roślina
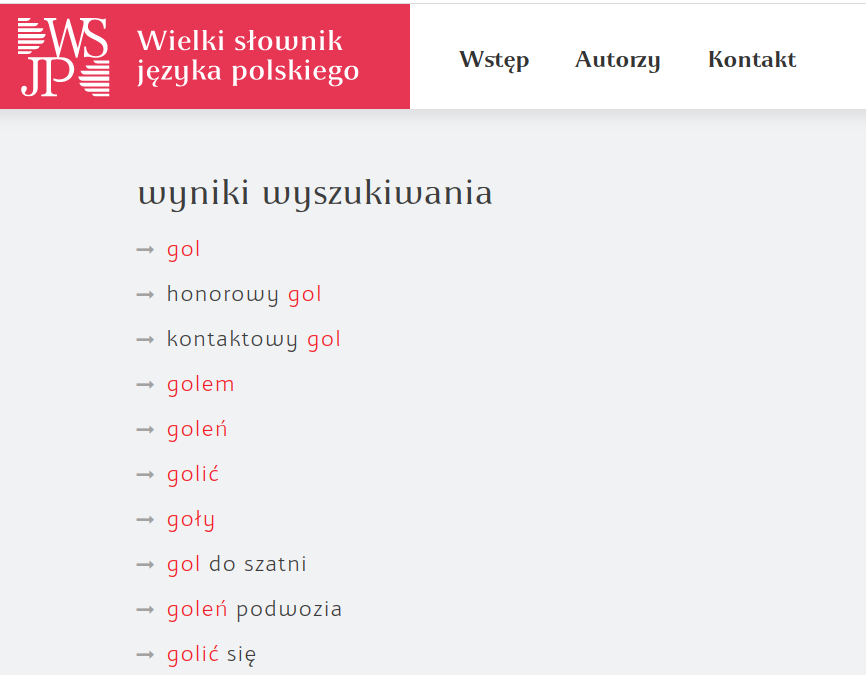
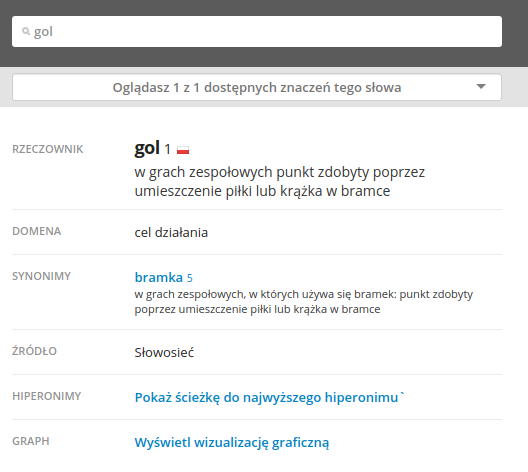
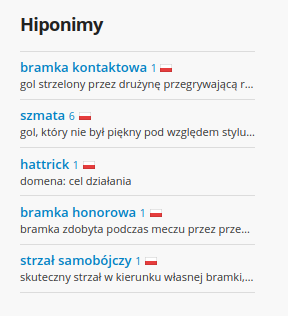
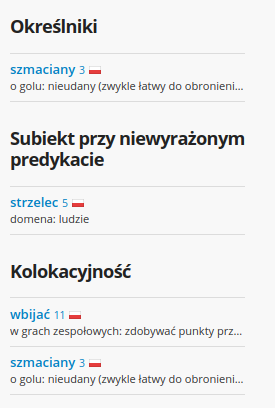
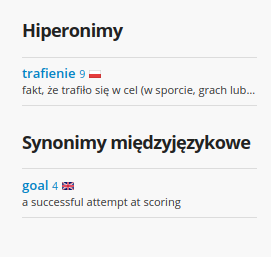
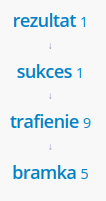
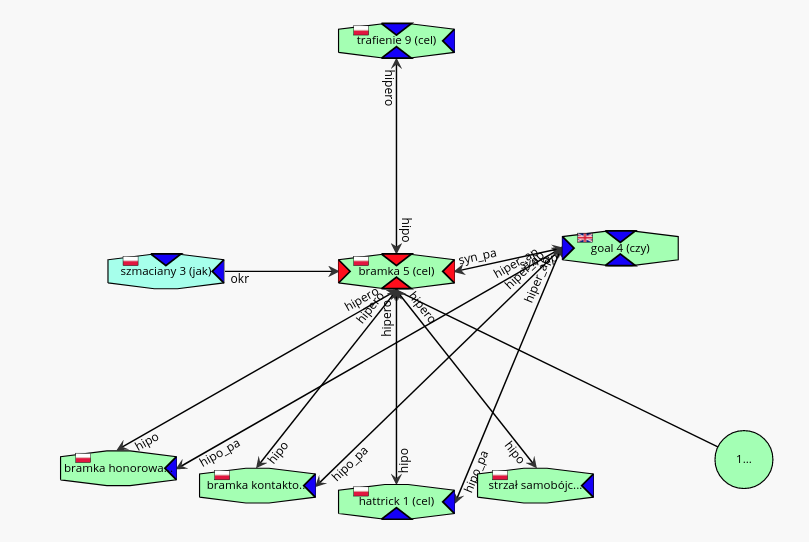
- W dzienniku mam jakąś ocenę
- W dzienniku mam jakąś jedynkę (?)
- W dzienniku mam jakiś gol (?)
- $\textrm{JEDYNKA} \subset \textrm{OCENA} \hspace{2cm} \forall x : \textrm{JEDYNKA}(x) \rightarrow \textrm{OCENA}(x)$ ?
czy
- $\textrm{JEDYNKA} \in \textrm{OCENA}$

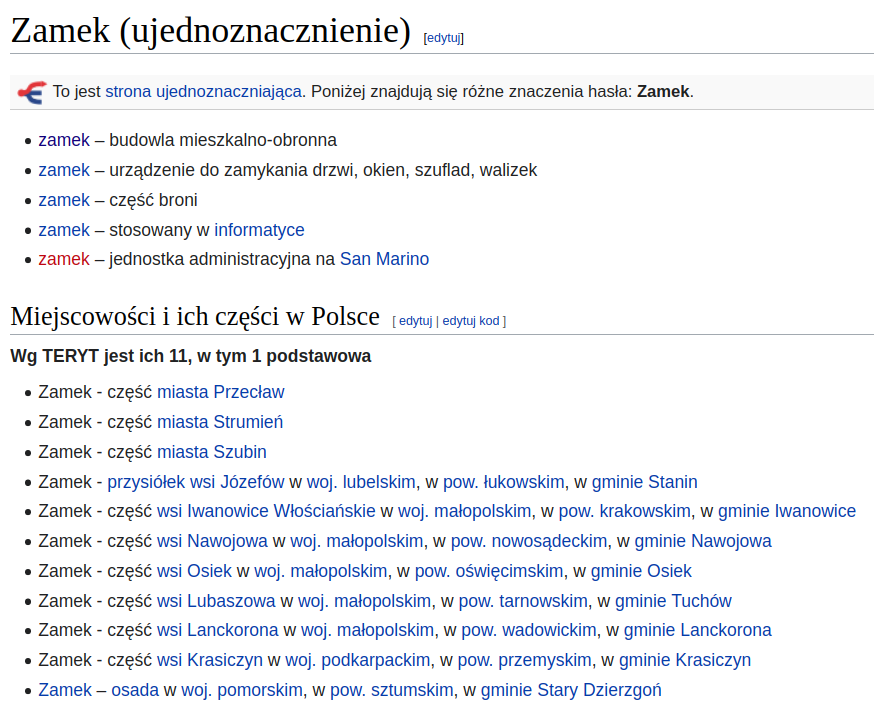
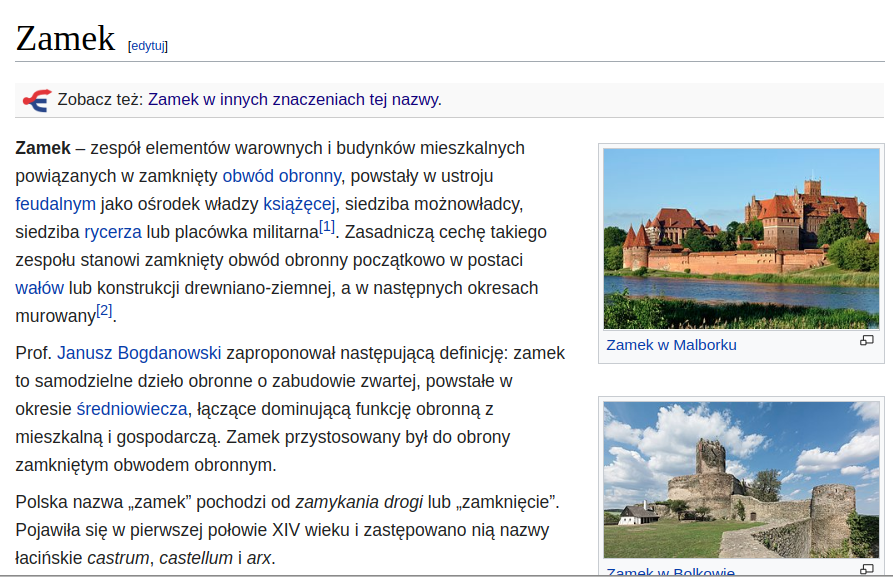
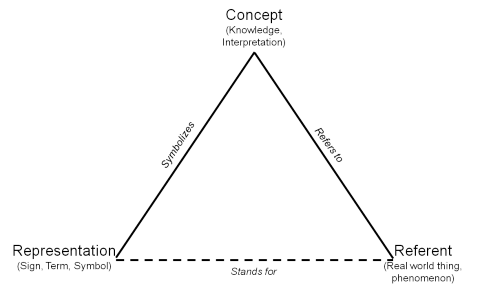
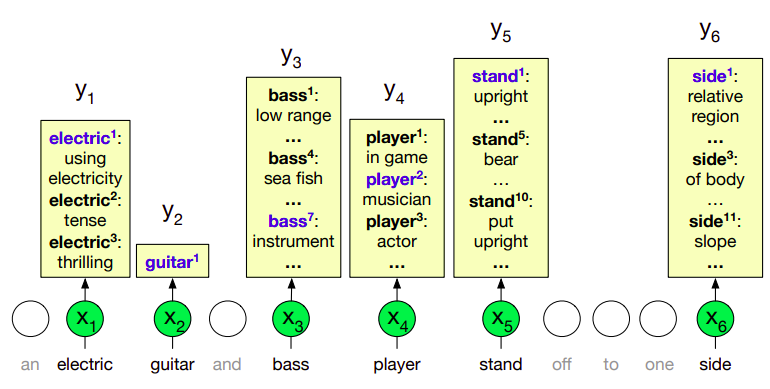
Ujednoznacznianie sensu¶
- wybranie sensu wyrażenia, które psuje do danego kontekstu
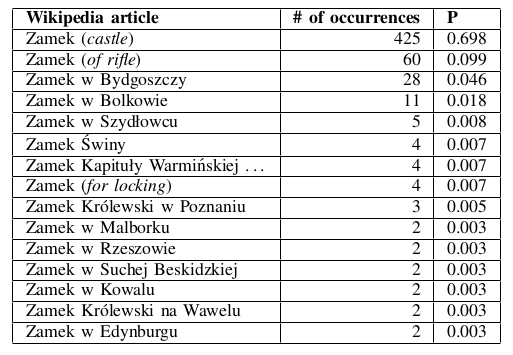
- Zamek na Wawelu jest piękny.
- Zamek wymaga naoliwienia.
Rodzaje dezambiguacji¶
- dezambiguacja wybranej grupy wyrazów
- dezambiguacja wszystkich wyrazów należacych do kategorii: rzeczownik, czasownik, przymiotnik, przysłówek
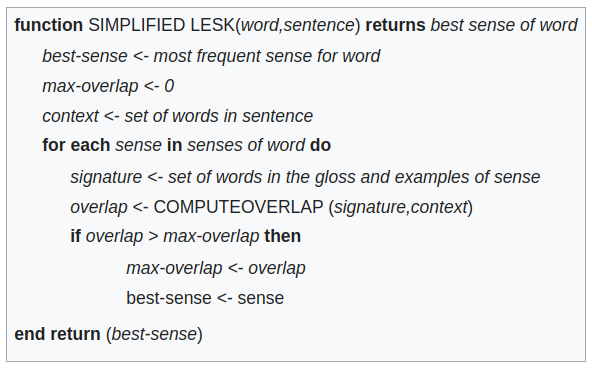
Rodzaje algorytmów¶
- nienadzorowane - wykorzystują tylko słownik oraz inne zasoby językowe
- nadzorowane - wykorzystują otagowany korpus
Algorytmy bazowe¶
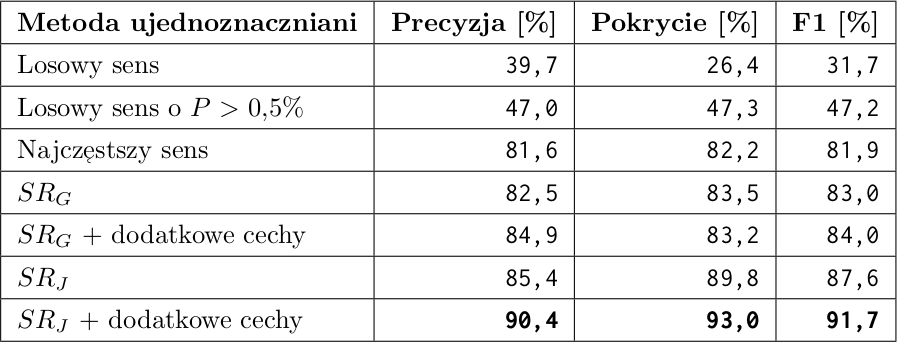
- wybranie najczęstszego sensu (Most Frequent Sense - MFS), pierwszy wpis w WordNecie
- jeden sens w jednym dokumencie
Anotowane korpusy¶
- SemCor (EN)
- Składnica (PL)
- PolEval 2020 (PL)
Precyzja: 58% na danych Senseval.
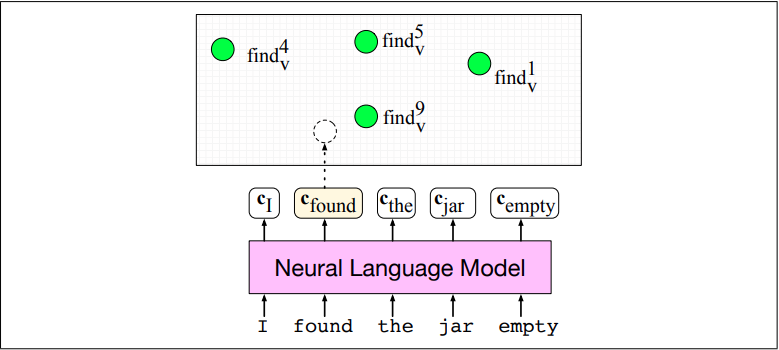
Oznaczenia¶
- $c$ - para
<jednostka leksykalna>-<synset>, np.find-1. (159) find, happen, chance, bump, encounter, zwana sensem, - $c_i$ - $i$-ty token, otagowany w korpusie jako należący do określonego $c$,
- $S_{\hat{S}}$ - zbiór osadzeń pozostałych sensów, w ramach danego synsetu, np.
happen-1. (159) find, happen, chance, bump, encounter, - $H_{\hat{S}}$ - zbiór osadzeń dla hiperonimów synsetu, do którego należy dany sens, np.
2. detect, observe, find, discover, notice$\rightarrow$spy, sight - $L_{\hat{S}}$ - zbiór osadzeń dla super-sensu (pojęcia stojącego na początku hierarchii synsetów)
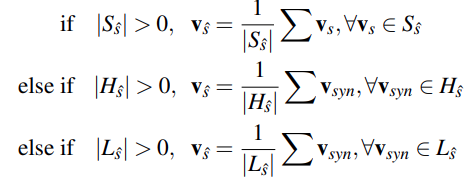
Cechy ujednoznaczniające¶
- prawdopodobieństwo sensu $P_{sense}(s_i, \sigma_j) = \frac{c(s_i, \sigma_j)}{c(s_i)}$
- prawdopodobieństwo odnośnika $P_{link}(s_i) = \frac{c_{link}(s_i)}{c_{total}(s_i)}$
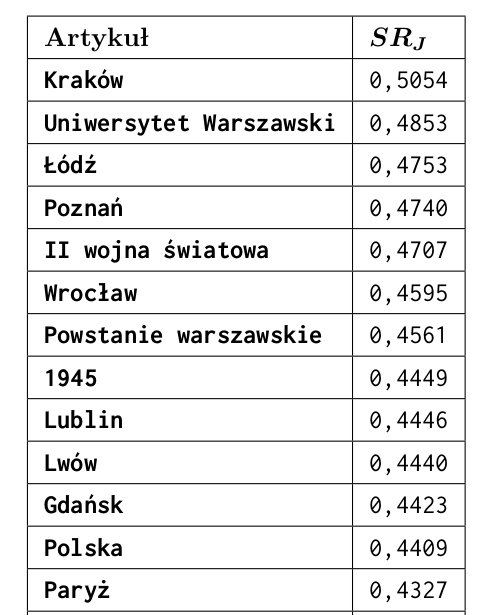
- średnie pokrewieństwo semantyczne $\overline{SR}(\sigma_i) = \frac{1}{n-1}\sum_{j=1,j\neq i}^{n}SR_J(\sigma_i, \sigma_j)$
- waga wyrażenia $W(\sigma_i) = \frac{\overline{SR}(\sigma_i)+P_{link}(\sigma_i)}{2}$
- jakość kontekstu $G(V) = \sum_{i=1}^{n}W(\sigma_i)$
Pokrewieństwo semantyczne¶
- $A$ - zbiór stron linkujących do strony $a$
- $B$ - zbiór stron linkujących do strony $b$