Klasyfikacja tekstu¶
Segmentacja obrazu¶

Klasyfikacja tekstu¶



Dziobak¶

s1: Zawodnik na boisku ze skórzaną rękawicą robi wykrok w przód na piasku.
s2: Mężczyzna w sportowym stroju stoi na ugiętej nodze na boisku, drugą nogę wystawiając do tyłu.
s1 względem s2 $\rightarrow$ neutral
s1: Żaden człowiek nie biegnie na boisku w kierunku lecącej piłki.
s2: Człowiek w sportowym stroju i kasku biegnie na boisku w kierunku lecącej piłki.
s1 względem s2 $\rightarrow$ contradiction
Przykład klasyfikacji wieloetykietowej tekstu¶
Kategorie DBpedii¶
Liu Chao-shiuan (Chinese: 劉兆玄; pinyin: Liú Zhàoxuán; born May 10, 1943) is a Taiwanese educator and politician. He is a former president of the National Tsing Hua University (1987–1993) and Soochow University (2004–2008) and a former Premier of the Republic of China (2008–2009).
Klasy: Agent, Politician, PrimeMinister
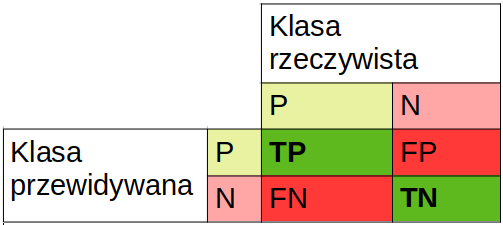
- dokładność (accurracy) $$ Acc = \frac{TP + TN}{TP + TN + FP + FN} $$
- czułość (recall)
$$Rc = \frac{TP}{TP + FN}$$
- wartość predykcyjna dodatnia (precision) $$Pr = \frac{TP}{TP + FP}$$
- miara F1 = $$\frac{2 * Rc * Pr}{Rc + Pr}$$
- współczynnik korelacji Matthews'a $$MCC = \frac{TP * TN - FP * FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}$$
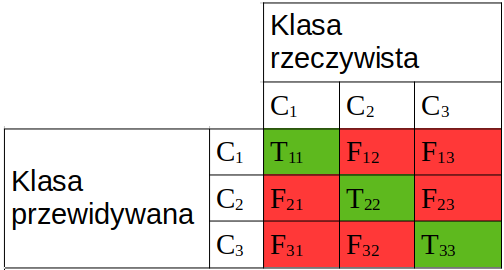
- macro $$Pr = \frac{\sum_{c \in C} Pr_{c}}{|C|}$$
- macro $$Rc = \frac{\sum_{c \in C} Rc_{c}}{|C|}$$
- weighted $$Pr = \frac{\sum_{c \in C} |c| * Pr_{c}}{\sum |c|}$$
- weighted $$Rc = \frac{\sum_{c \in C} |c| * Rc_{c}}{\sum |c|}$$
- micro-F1 = Acc
Algorytm klasyfikacji oparty o regułę Bayesa¶
Reguła Bayesa:
$$P(A\land B) = P(A|B) * P(B) = P(B|A) * P(A)$$z czego:
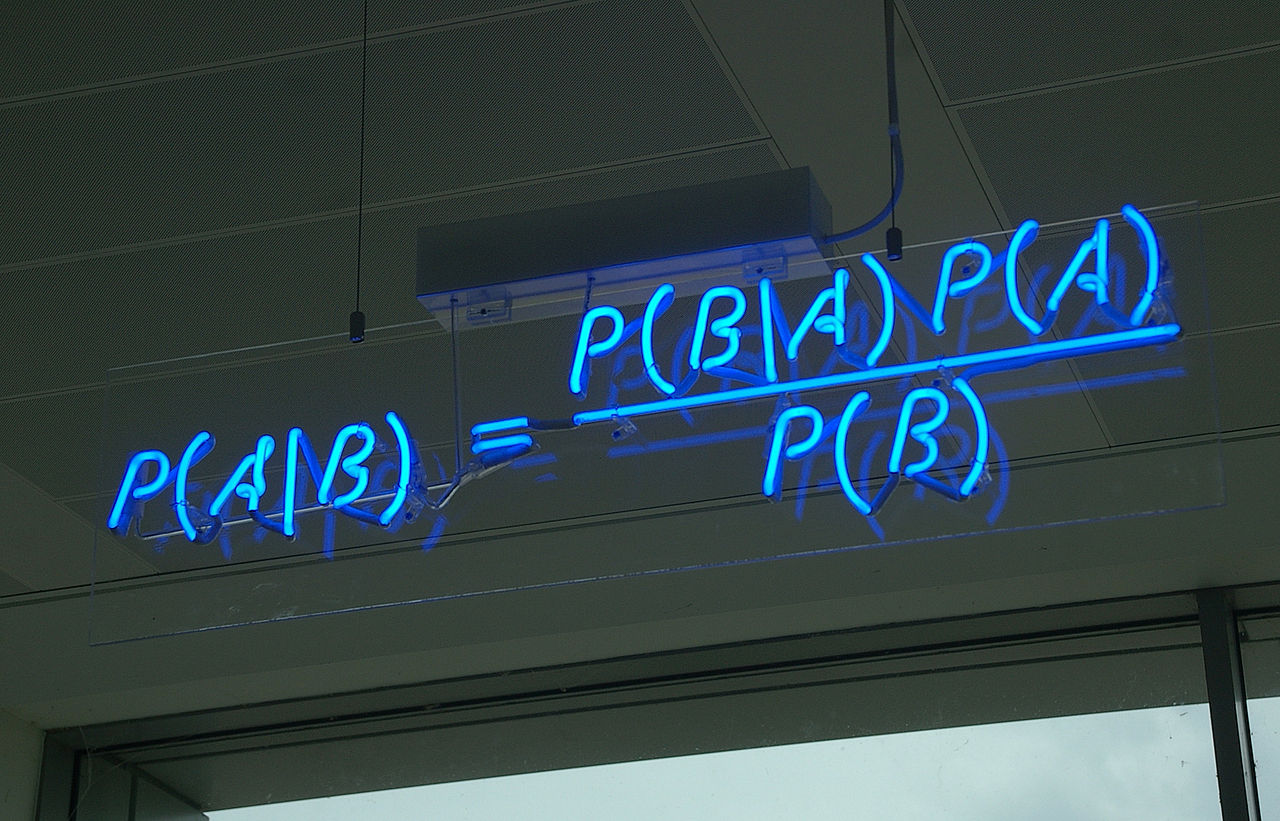
Reguła Bayesa¶
$$P(A|B) = \frac{P(B|A) * P(A)}{P(B)}$$- $A$ - Dokument jest spamem $S$
- $B$ - Dokument zawiera wyraz milion $M$
$D$ - dokument zawierający słowa $w_i \in D$.
$$P(S|D) \cong \Pi_{w_i \in D} P(S|w_i) \propto P(S) * \Pi_{w_i \in D} P(w_i|S)$$
Przykłady regresji tekstowej¶
Według mnie statyw na początku był bardzo fajny miał dużo możliwości, ale po drugim dniu chciałem zrobić dobre ujęcie lecz noga od statywu odłamała się a po tygodniu, w podróży odłamała się kolejna. Pózniej okazało się ,że statyw nie jest taki wytrzymały i w konsekwencji straciłem trzecią nogę od statywu. Niestety statyw był bardzo złej jakości. 
Wykonanie przeciętne . Krajalnicy nie używamy co 10 min. w ciągu dnia więc denerwujące jest rozkładanie krajalnicy i nakładanie wózka krajalnicy bo bez wózka nie można ukroić nawet kromki chleba. Płyta regulacji grubości krojenia niestabilna co powoduje że wędlina jest krojona nierówno. Przyssawki tak mocne że zostają przyssane do blatu i trzeba je odrywać i nakładać na krajalnicę. Urządzenie niczym się nie wyróżnia. Nie polecam ale wybór należy do kupującego. 
Brak odpowiedniej instrukcji montażu - spasowanie prawie ok - czarna ramka zasłania ok 1 mm ekranu przy idealnym spasowaniu otworów aparatu przedniego. Poza tym patent z czarną ramką jest rewelacyjny - ekran ma zaokrąglane rogi i naklejone szkło zawsze w tym miejscu odstaje i wygląda nieestetycznie -tu tego problemu nie ma bo ramka to zakrywa i wygląda to idealnie. 
Miary poprawności regresji¶
- Współczynnik korelacji Pearson'a $PCC(X,Y) = \frac{COV(X, Y)}{\sigma_X\sigma_Y}$
- Współczynnik korelacji Spearmana $SRCC = PCC(rank(X), rank(Y)$