

Struktura problemu QA¶
- przeszukiwania tekstów - selective question answering
- znajdowanie odpowiedzi - extractvie question answering
Selective QA¶
- zależy mocno od domeny problemu:
- Jeopardy - Wikipedia
- wyszukiwanie artykułów naukowych
- wyszukiwanie przepisów prawa
- wyszukiwanie orzeczeń
- różne możliwe podejścia
- FTS + model neuronalny
- tylko model neuronalny
- kluczem jest szybkość wyszukiwania
- ElasticSearch + NBoost
- FAISS



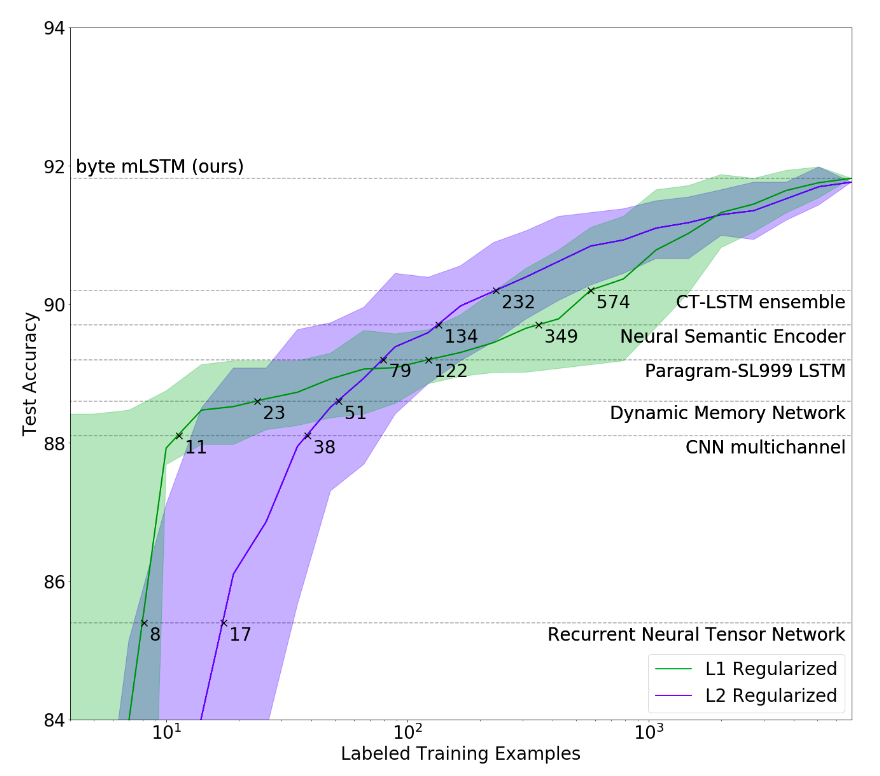
Przeuczenie modelu¶
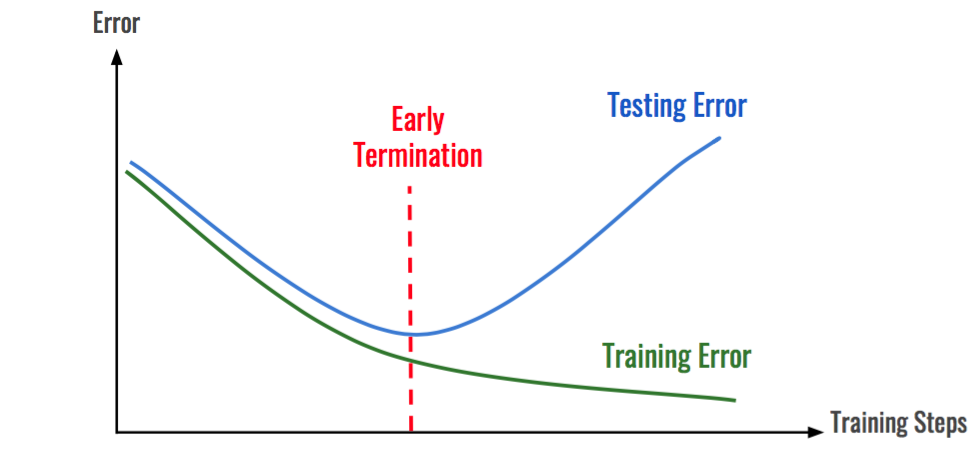
GPT-1 - OpenAI¶

GPT-2 - OpenAI¶

Źródło: "Language Models are Unsupervised Multitask Learners" A. Radford, J. Wu, R. Child, D. Luan,D. Amodei, I. Sutskever

Istota mechanizmu atencji¶
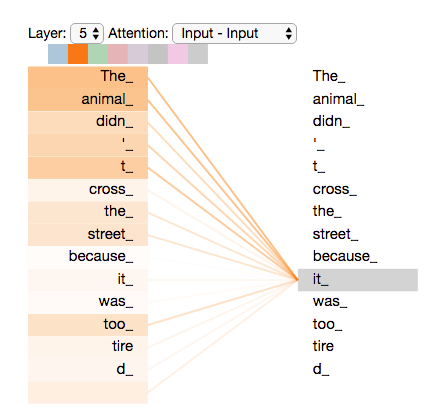
- The animal didn't cross the street because it was too tired.
- The animal didn't cross the street because it was too crowded.
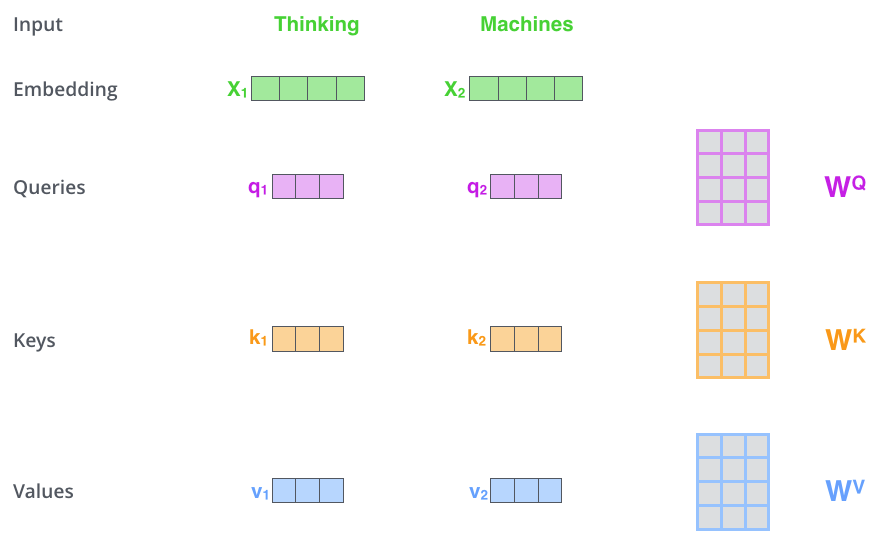
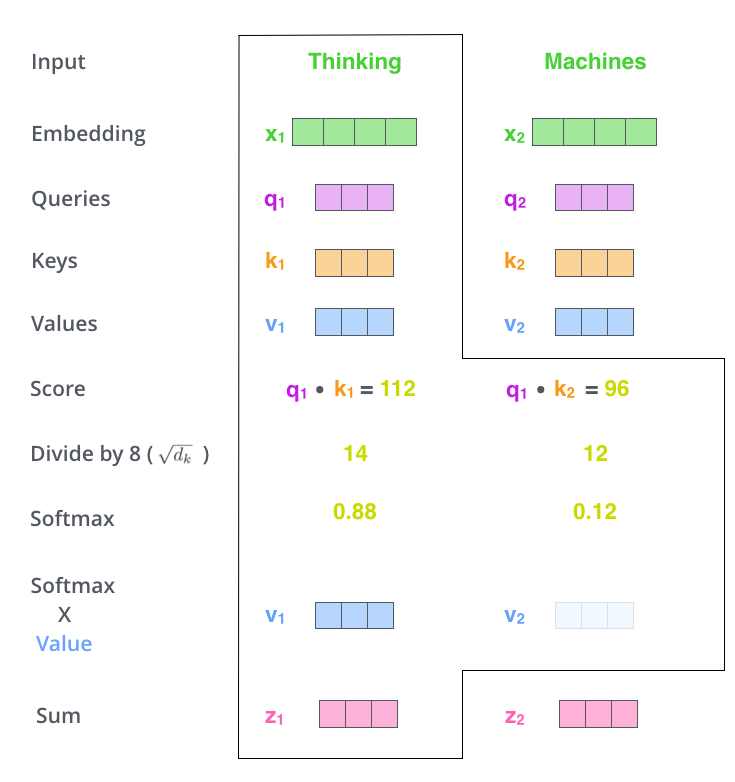
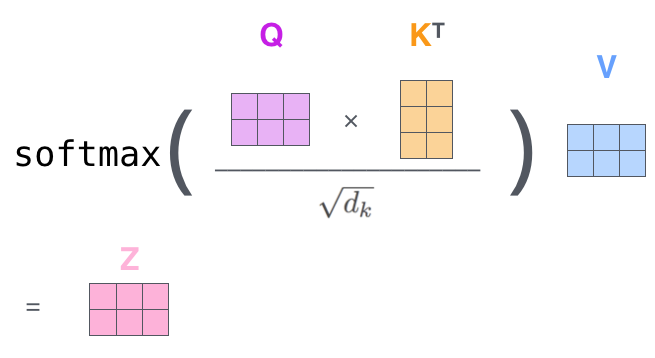

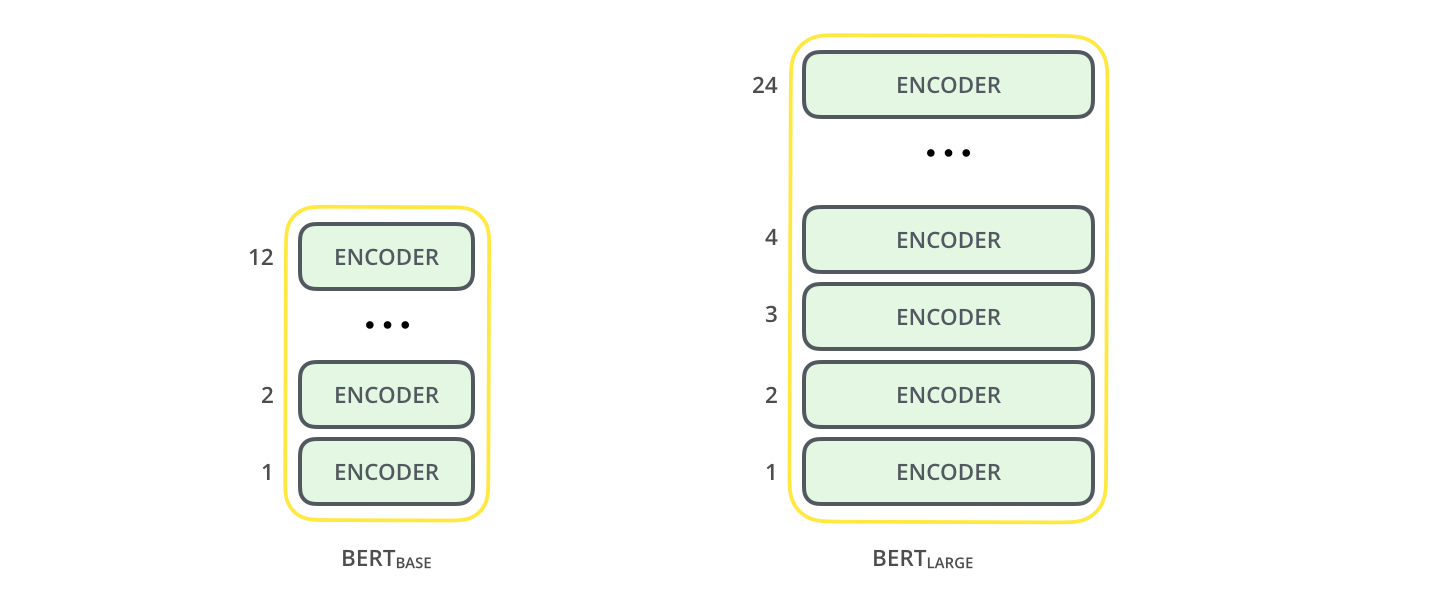
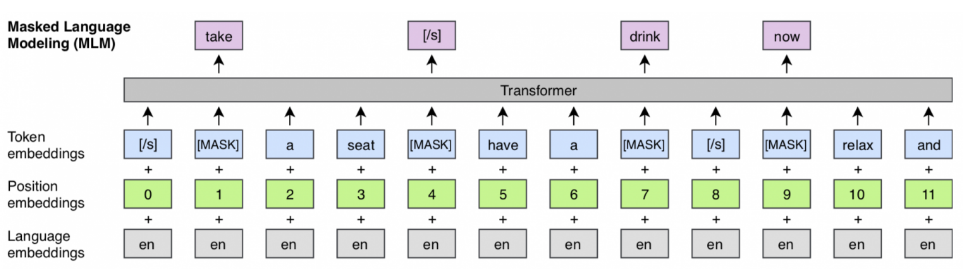
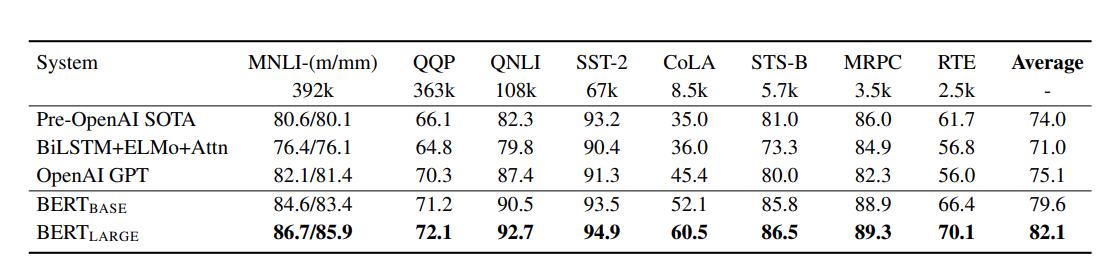
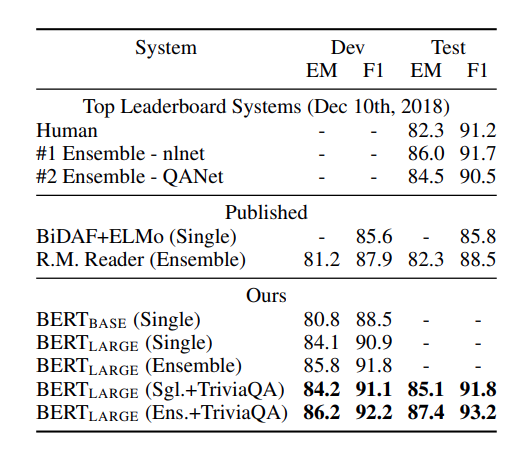
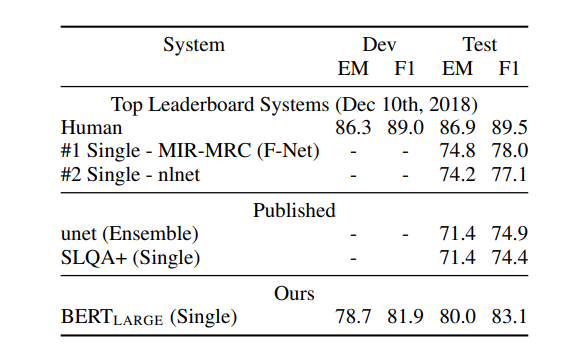
Warianty BERTa¶
- architekturalne
- Albert
- XLNet
- BART
- ...
- pretrenowane
- RoBERTa, XLMR
- FlauBERT
- FinBERT
- PolBERT
- HerBERT
- ...
Selektywne odpowiadanie na pytania¶
- SOLR/ElasticSearch
- ElasticSearch + NBoost
- REALM
- Dense Passage Retriver
Założenia odpowiadania selektywnego¶
- wybór 10-1000 wyników spośród milionów dostępnych dokumentów
- wysoka szybkość działania (10-100ms dla zbiorów zawierających miliony dokumentów)
REALM - Retrieval-Augmented Language Model Pre-Training (Google)¶
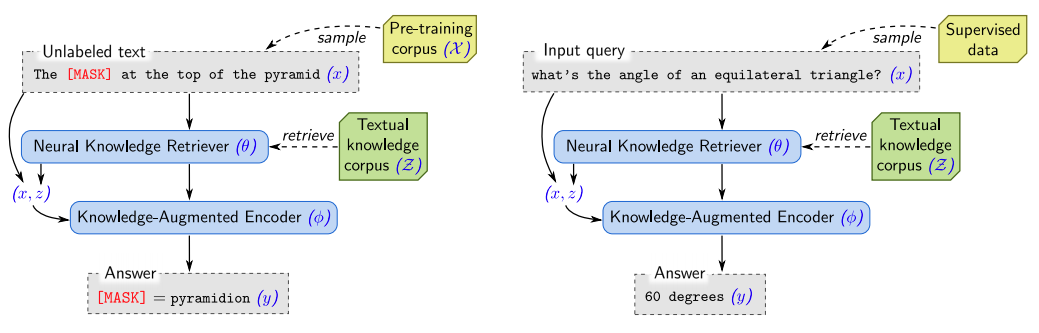
- pre-trening - uczony jest MLM, który wspomaga się fragmentami tekstu z korpusu
- fine-tuning - model odpowiadający na pytania, na podstawie znalezionych fragmentów
$$
p(y|x)
$$
- pre-training: $x$ - zdanie, $y$ - zamaskowany token
- fine-tuning: $x$ - pytanie, $y$ - odpowiedź
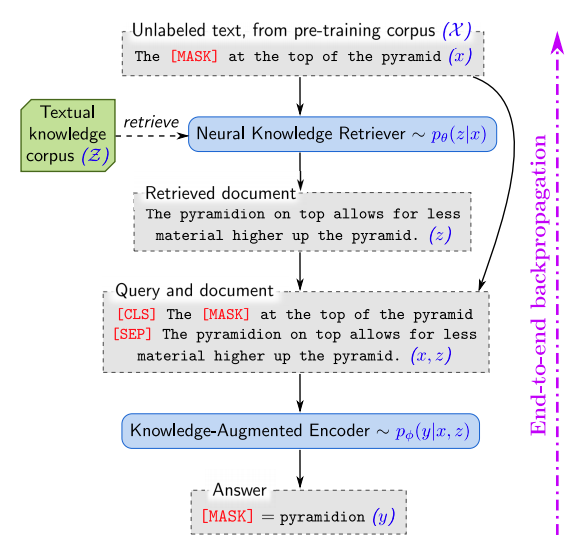
Pre-training¶
$Z$ - zbiór dokumentów $z$, które pomagaja odgadnąć token ($|Z|$ - miliony dokumentów)
$p(z|x)$ - określenie przydatnych dokumentów
$p(y|x,z)$ - odgadnięcie najbardziej prawdopodobnych zamaskowanych wyrazów na podstawie zdania $x$ i dokumentu $z$
$$
p(y|x) = \sum_{z \in Z}p(y|x,z)p(z|x)
$$
Knowledge retriver¶
$$
p(z|x) = \frac{\text{exp} f(x,z)}{\sum_{z'}\text{exp} f(x,z')}
$$
$$
f(x,z) = E_{I}(x)^{T}E_{D}(z)
$$
$$
\text{join}_{B}(x) = \text{[CLS]}x\text{[SEP]}
$$
$$
\text{join}_{B}(x_1,x_2) = \text{[CLS]}x_1\text{[SEP]}x_2\text{[SEP]}
$$
$$
E_{I}(x) = W_{I}B_{\text{CLS}}(\text{join}_{B}(x))
$$
$$
E_{D}(z) = W_{D}B_{\text{CLS}}(\text{join}_{B}(z_{\text{title}}, z_{\text{body}}))
$$
Knowledge augumented encoder¶
$$
p(y|x,z) = \Pi_{j=1}^{J_x}p(y_j|x,z)
$$
$$
p(y_j|x,z) \propto \text{exp}\left(w_j^{T}B_{\text{MASK}(j)}(\text{join}_{B}(x,z_{\text{body}}))\right)
$$
$$
p(y|x,z) \propto \sum_{s\in S(z,y)}\text{exp}\left(\text{MLP}\left([h_{\text{start(s)}};h_{\text{end(s)}}]\right)\right)
$$
$$
h_{\text{start(s)}} = B_{\text{start(s)}}(\text{join}_{B}(x,z_{\text{body}}))
$$
$$
h_{\text{end(s)}} = B_{\text{end(s)}}(\text{join}_{B}(x,z_{\text{body}}))
$$
Trening¶
- podstawowy problem - obliczenie $p(y|x) = \sum_{z\in Z}p(y|x,z)p(z|x) \rightarrow$ ogranicznie do top-k dokumentów
- użycie algorytmu MIPS do znalezienia top-k dokumentów
- wymaga to obliczenia $E_{D}(z)$ dla wszystkich dokumentów w zbiorze $\rightarrow$ asynchroniczna aktualizacja indeksu, obliczenie nowych osadzeń dla top-k dokumentów
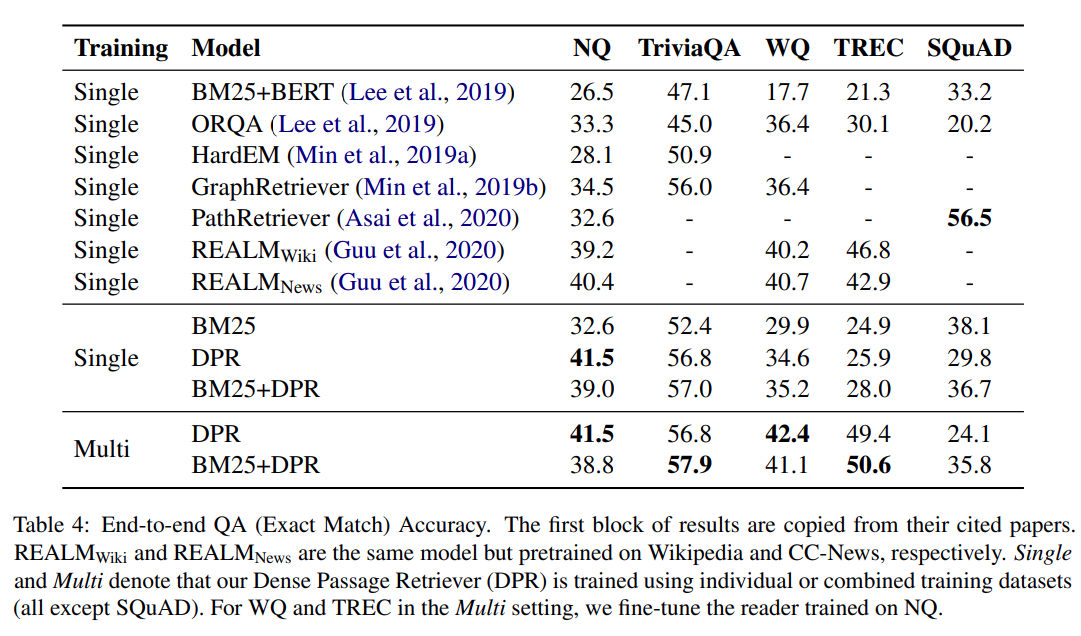
Zbiory danych¶
- NQ - natural questions, pytania użytkowników Google
- WQ - web questions, Google Suggest API
- CT - curated Trec, MSNSearch, AskJeeves
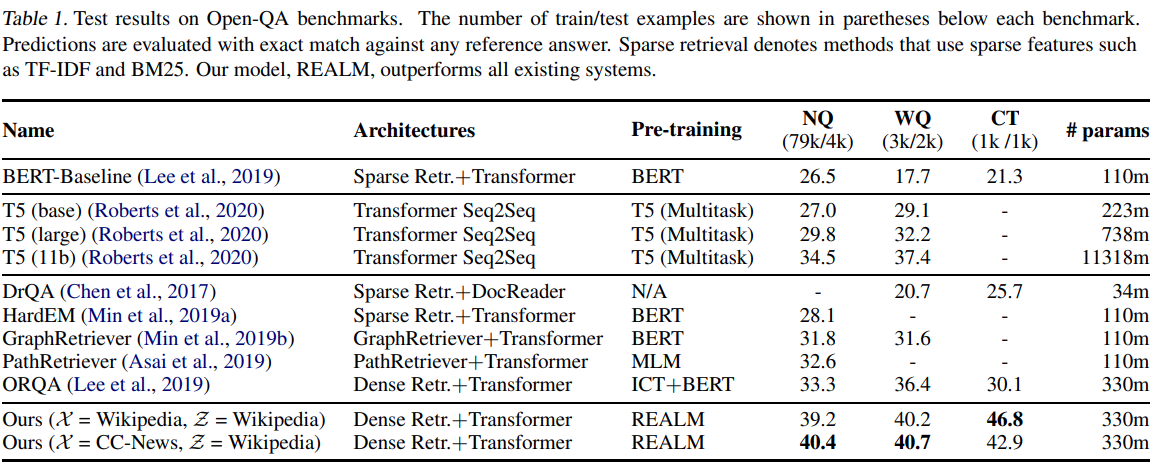
DPR - Dense Passage Retriver (Facebook)¶
$E_{P}(\cdot)$ - enokoder dla fragemtnów dokumentów
$E_{Q}(\cdot)$ - enkoder dla pytań
$sim(q,p) = E_{Q}(q)^{T}E_{P}(p)$
$E_{P}(\cdot), E_{Q}(\cdot)$ - są osobnymi sieciami opartymi o BERTa (tzn. mają zestaw parametrów trenowanych niezależnie).
Indeksowanie i inferencja¶
- dla każdego fragmentu aplikowana jest funkcje $E_{P}(\cdot)$
- fragmenty mają rozmiar 100 wyrazów
- dane składowane są w indeksie FAISS (podobnie jak w przypadku ES/SOLR jest to kosztowna operacja)
- zapytanie jest zamieniane z użyciem funkcji $E_{Q}(\cdot)$
- wyniki wyszukiwane są w czasie sub-liniowym
Trening modelu¶
$$
D = \{\langle q_i, p_i^{+}, p_{i,1}^{-}, p_{i,2}^{-}, \cdots, p_{i,n}^{-} \rangle\}^{m}_{i=1}
$$
$$
L(q_i, p_i^{+}, p_{i,1}^{-}, p_{i,2}^{-}, \cdots, p_{i,n}^{-}) = - log \frac{e^{sim(q_i, p_i^{+})}}{e^{sim(q_i, p_i^{+})} + \sum_{j=1}^{n}e^{sim(q_i,p_{i,j}^{-})}}
$$
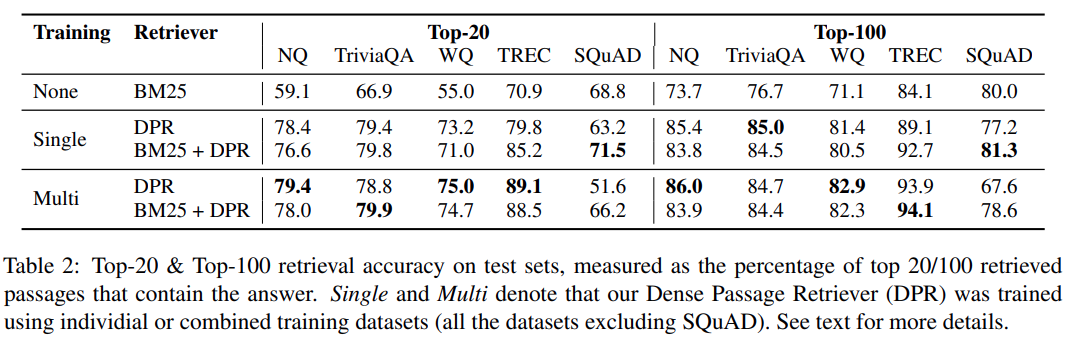
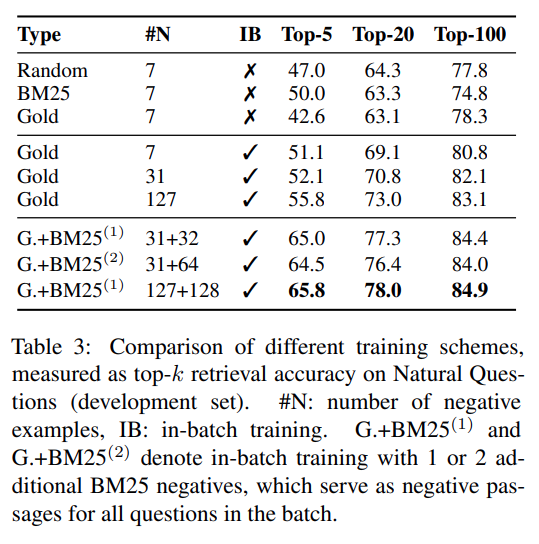
Strategie wyboru negatywnych przykładów
- losowa
- BM25
- wybór przykładów z innych odpowiedzi w tym samym batchu (nazywana gold w artykule)
Strategia gold¶
- $Q$, $P$ - macierze $B$ osadzeń dla pytań i fragmentów dokumentów o rozmiarze $B \times d$
- $S = QP^{T}$ - macierz rozmiaru $B \times B$ podobieństwa pytań do fragmentów
- każda para $(q_i, p_j)$ jest pozytywna, jeśli $i=j$, a negatywna w przeciwnym razie
Literatura¶
- Vaswani, Ashish, et al. Attention is all you need. Advances in neural information processing systems. 2017.
- Devlin, Jacob, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- The Illustrated transformer
- The Illustrated BERT
- REALM: Retrieval-Augmented Language Model Pre-Training
- Dense Passage Retriver
- Rozdział 9 SLP