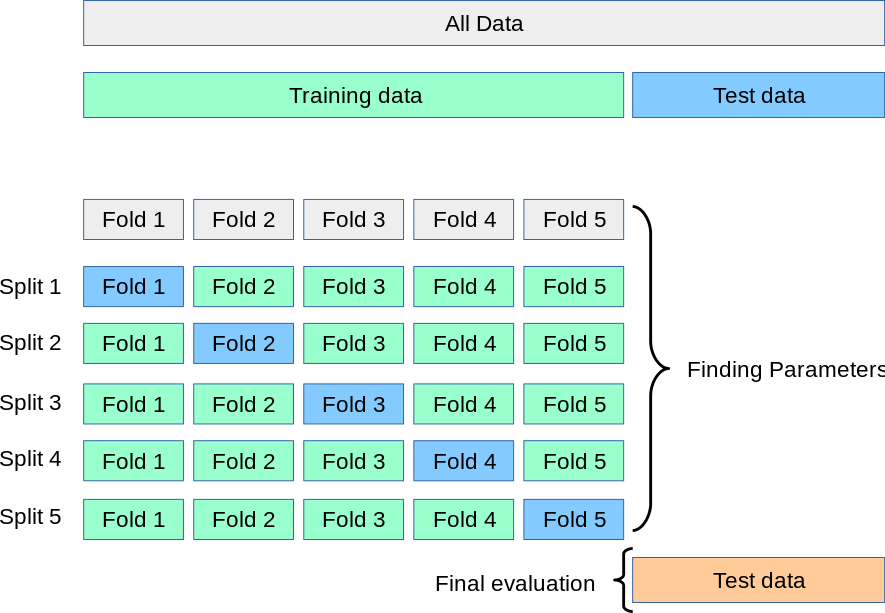
Jakie istnieją formy uczenia?¶
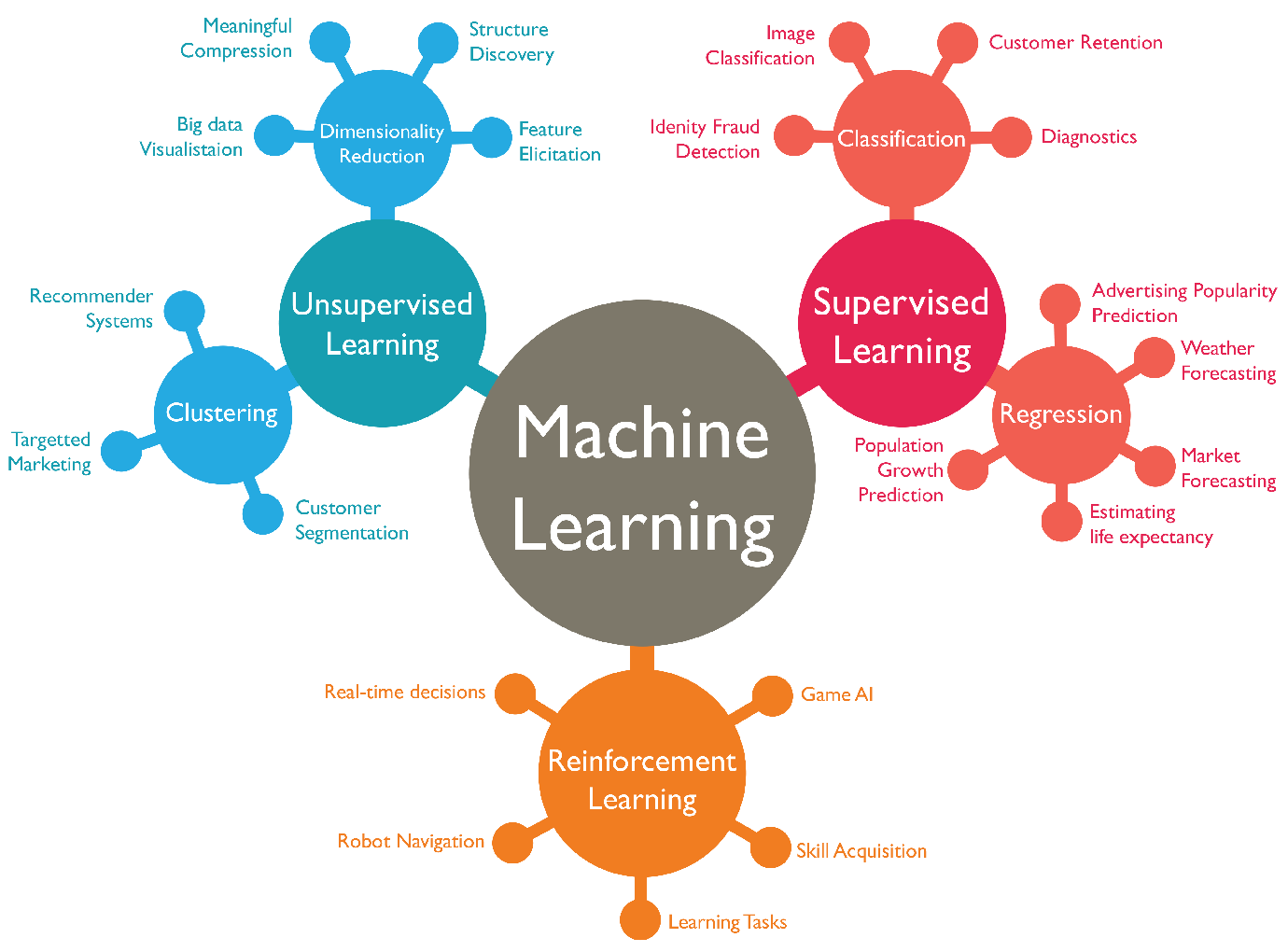
- Uczenie nadzorowane - supervised learning
- Uczenie nienadzorowane - unsupervised learning
- Uczenie ze wzmocnieniem - reinforcement learning

Regresja - drugi podstawowy typ uczenia nadzorowanego¶
https://www.bbc.com/news/science-environment-36888541
Dane wejściowe¶
- wartości liczbowe: dyskretne, ciągłe, np. temperatura, cena, liczba studentów, itp.
- wartości kategoryczne: dyskretny, skończony, nieuporządkowany zbiór wartości, np. narodowość, przedmiot na studiach, marka samochodu, płeć, itp.
- wartości binarne: szczególny typ wartości kategorycznych, objemujący tylko 2 wartości: 0 i 1, prawda/fałsz, etc.

https://huggingface.co/datasets/maharshipandya/spotify-tracks-dataset/viewer/default/train
Ocena na podstawie recenzji - regresja, czy klasyfikacja?¶

https://christinesunflower.com/2016/02/09/on-book-reviews-and-the-stars-rating-system/
Jak można uczyć model bez nadzoru?¶
Uczenie nienadzorowane - klasteryzacja¶

https://www.kdnuggets.com/2019/09/hierarchical-clustering.html
Modelowanie tematów - przykład redukcji wymiarowości¶
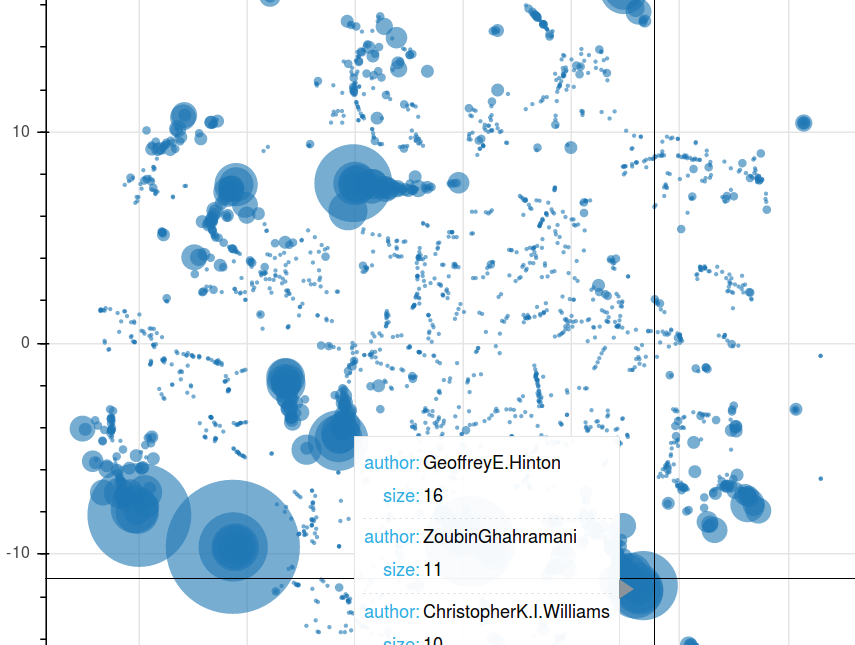
https://rare-technologies.com/new-gensim-feature-author-topic-modeling-lda-with-metadata/
Maskowane modelowanie języka - uczenie samonadzorowane¶
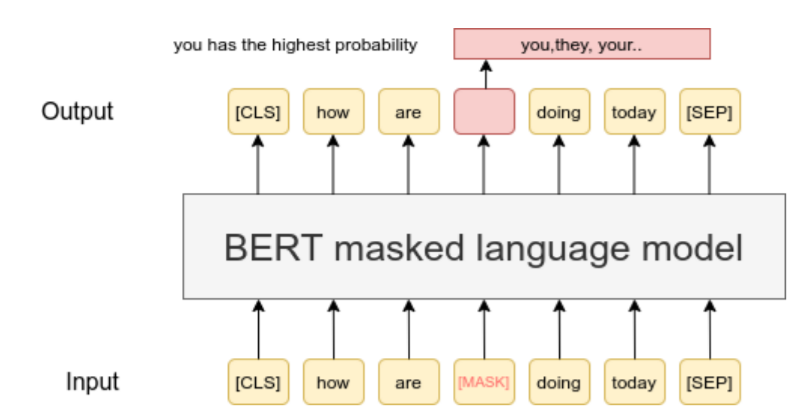
https://www.sbert.net/examples/unsupervised_learning/MLM/README.html


Uczenie nadzorowane - definicja¶
Mając dany zbiór treningowy par
$$ (x_1, y_1), (x_2, y_2), (x_3, y_3), \ldots, (x_n, y_n) $$generowanych przez funkcję $f(x)$, znaleźć funkcję $h$, która aproksymuje funkcję $f$.
Funkcja $h$ zwana jest hipotezą, a przestrzeń z której jest wybierana przestrzenią hipotez H.
Alternatywnie mówimy, że $h$ jest modelem danych, wybieranym z określonej klasy modeli H.
Dopasowanie hipotezy do danych¶
Oczekujemy, że funkcja $h$ będzie spójna z danymi uczącymi, tzn. najlepiej jeśli $h(x_i) = y_i$.
S. Russel, P. Norvig, AIMA 4rd edition
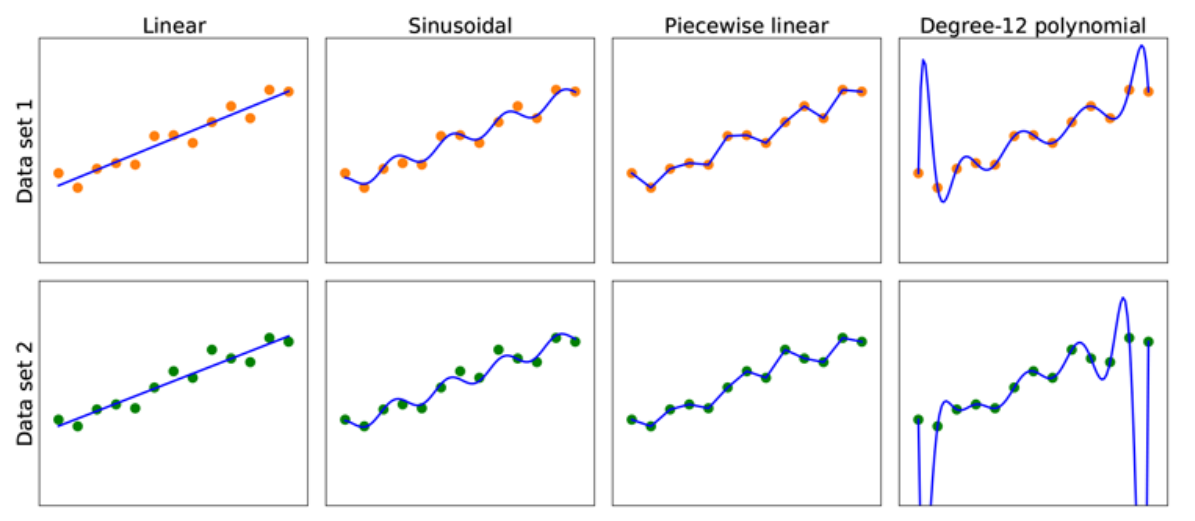
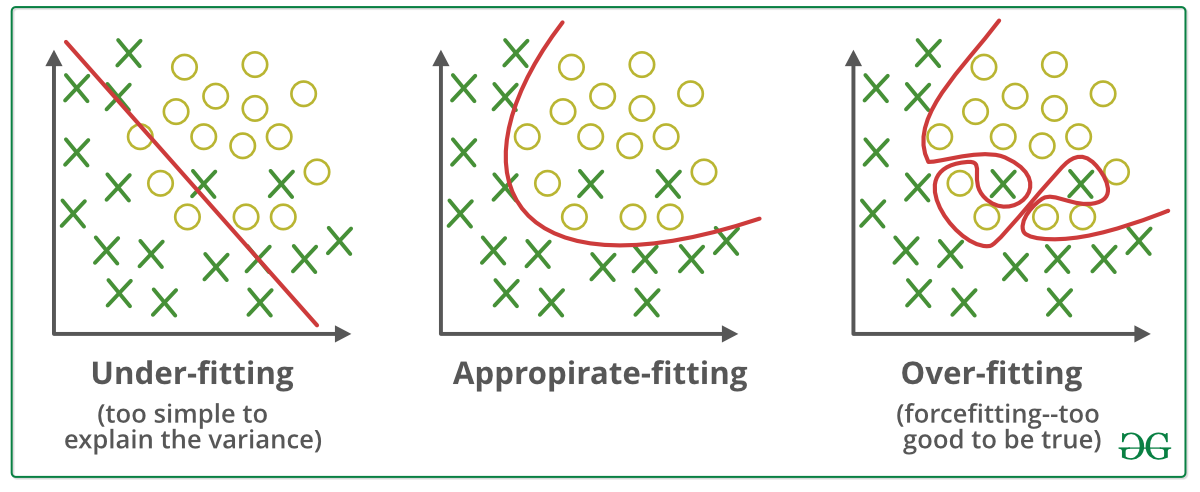
Obciążenie i wariancja¶
Obciążenie - tendencja hipotezy $h$ do różnienia się od oczekiwanego wyniku (wartości oczekiwanej), w przypadku treningu na różnych zbiorach danych.
Niedopasowanie (ang. underfitting) - niezdolność hipotezy do właściwego odwzorowania danych uczących.
Wariancja - zmienność wyniku funkcji, wynikająca z (niewielkich) zmian w danych.
Przeuczenie lub nadmierne dopasowanie (ang. overfitting) - zbyt dokładne dopasowanie hipotezy do zbioru uczącego.
Kompromis między obciążeniem a wariancją (ang. bias-variance tradeoff) - wybór pomiędzy bardziej złożoną hipotezą, która dobrze dopasowuje się do danych, a prostszą hipotezą, która może lepiej się generalizować.
Generalizacja - zdolność modelu do generowania poprawnych wartości funkcji, na danych spoza dystrybucji danych uczących.

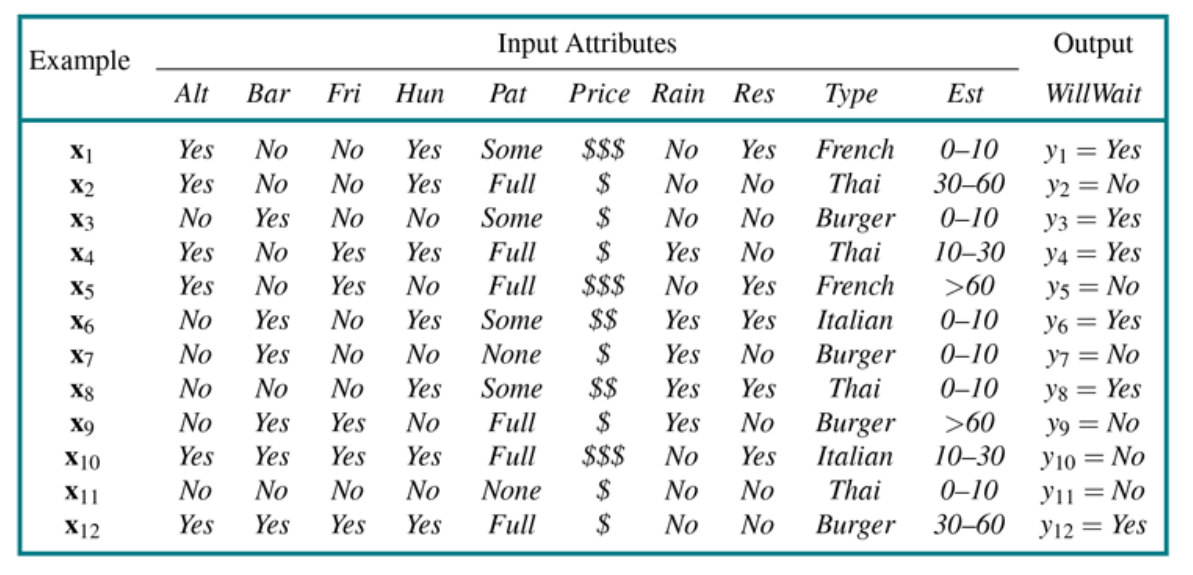
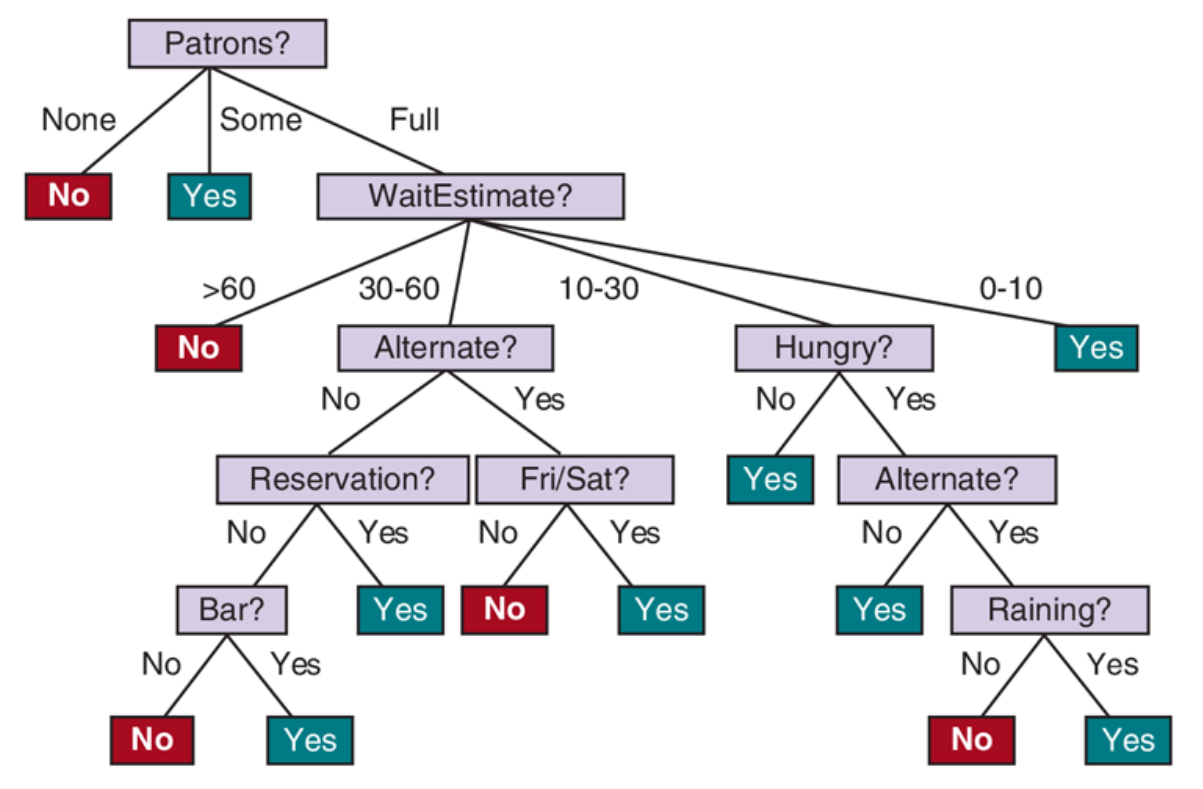
Jak powinniśmy wybierać atrybuty, żeby drzewo było najmniejsze?¶
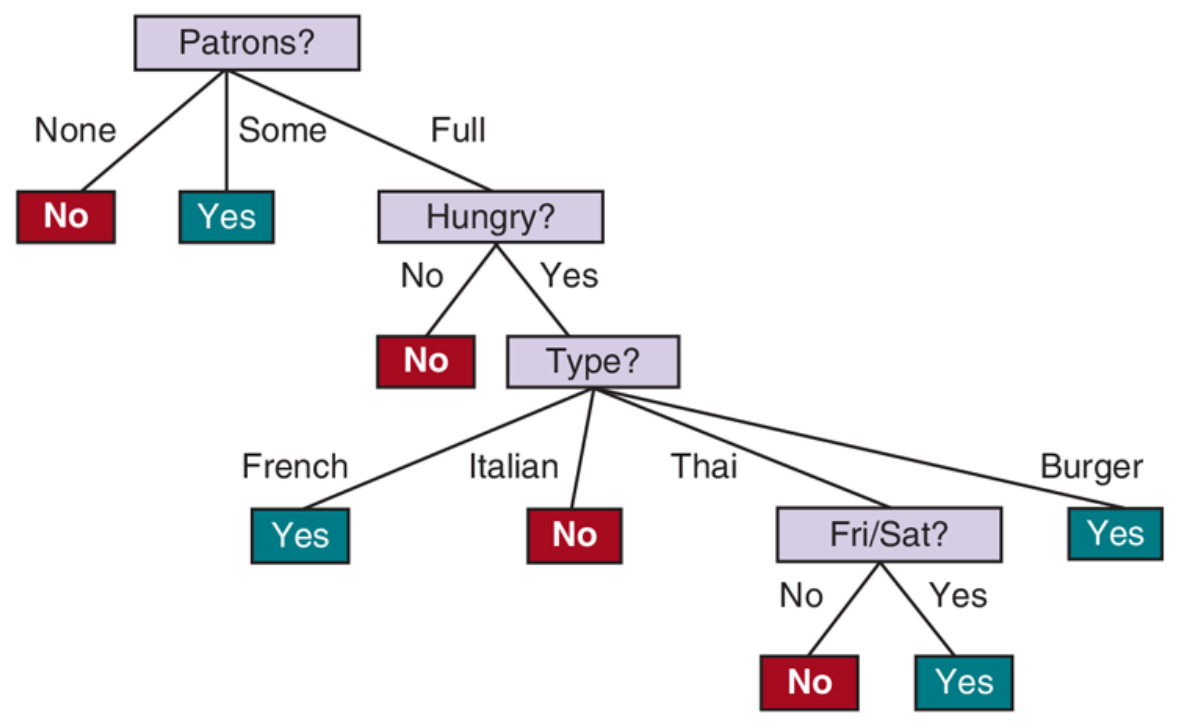
Indukcja drzewa decyzyjnego - hipotezy $\hat h_1(x)$ i $\hat h_2(x)$¶
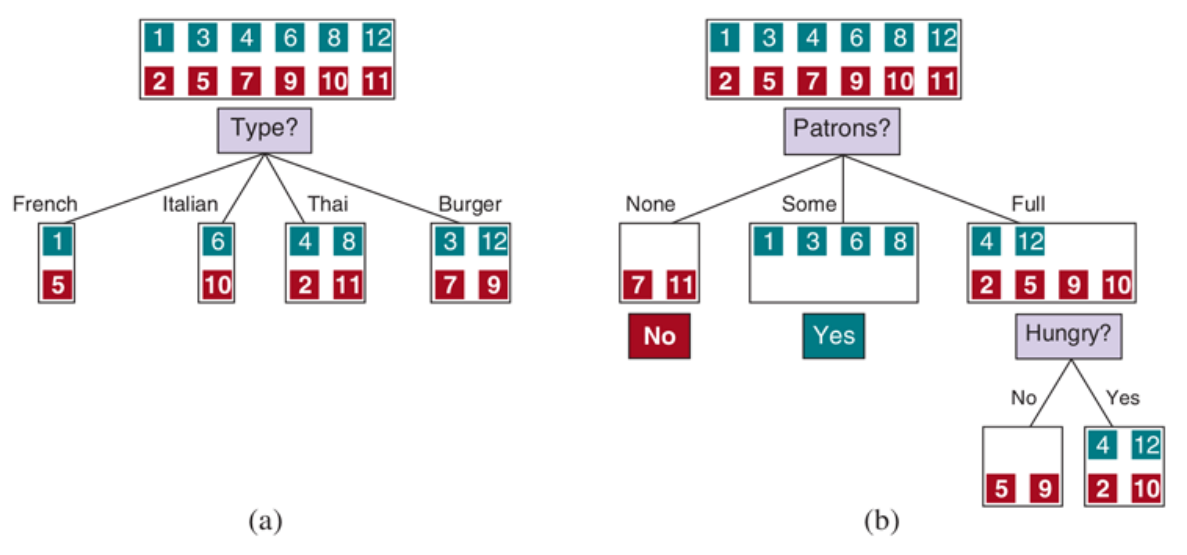
S. Russel, P. Norvig, AIMA 4rd edition.

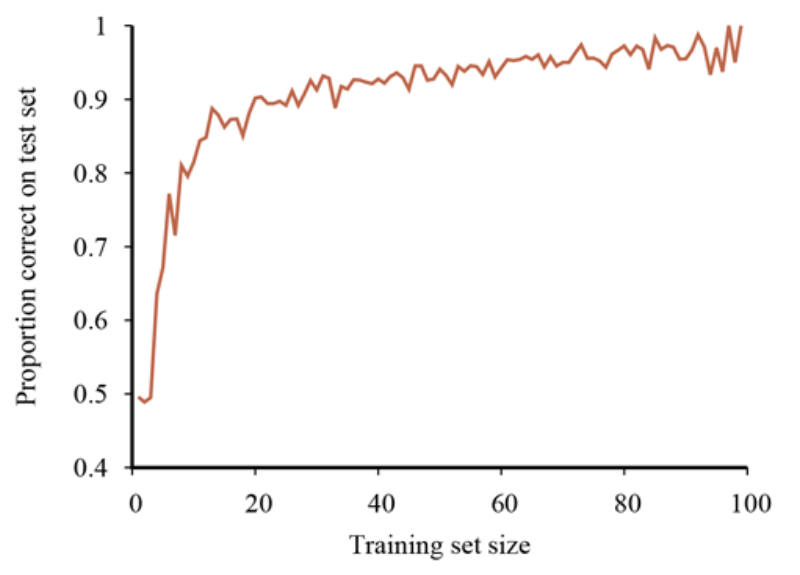
Entropia i przyrost informacji¶
Entropia - miara niepewności na temat zmiennej losowej. Entropia jest tym mniejsza im więcej wiemy na temat zmiennej losowej.
- $H$ - entropia
- $V$ - zmienna losowa
- $v_k$ - wartości zmiennej losowej
- $P(v_k)$ - prawdopodobieństwo wartości $v_k$
- $B$ - entropia binarnej zmiennej losowej
- $q$ - prawdopodobieństwo klasy pozytywnej
- $p$ - liczba przykładów pozytywnych
- $n$ - liczba przykładów negatywnych
- $A$ - wybrany atrybut drzewa decyzyjnego
- $d$ - liczba wartości atrybutu $A$
- $E_1$ - $E_d$ - podzbiory przykładów pozostające po wybraniu atrybutu $A$
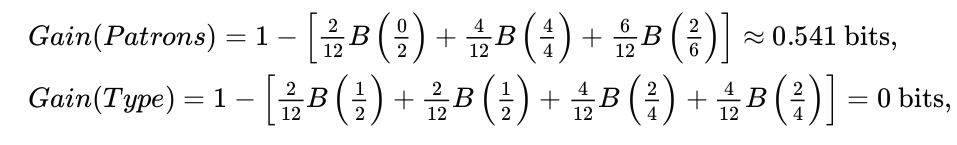
S. Russel, P. Norvig, AIMA 4rd edition.
Ocena modeli uczenia maszynowego¶

https://www.studying-in-uk.org/information-on-predicted-grades-for-independent-applicants-in-the-uk/
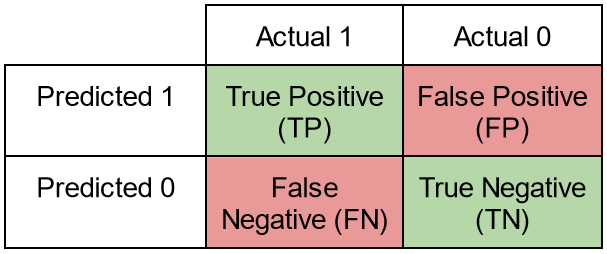
Przypadki
- prawdziwie pozytywne (true positive TP) - model zwrócił klasę pozytywną (positive), i jest to prawda (true)
- prawdziwie negatwyne (true negative TN) - model zwrócił klasę negatywną (negative), i jest to prawda (true)
- fałszywie negatywne (false negative FN) - model zwrócił klasę negatywną (negative), ale nie jest to prawda (false)
- fałszywie pozytywne (false positive FP) - model zwrócił klasę pozytywną (positive), ale nie jest to prawda (false)
Dokładność (celność, accuracy)¶
Dlaczego nie wystarcza nam dokładność?¶
Zbiór zbalansowany i niezbalansowany¶

Precyzja, miara predykcyjna dodatnia (precision)¶
$$ Pr = \frac{TP}{TP + FP} $$Czułość, pokrycie (recall)¶
$$ Rc = \frac{TP}{TP + FN} $$Miara $F_1$¶
$$ F_1 = \frac{2 Pr Rc}{Pr + Rc} $$Miara $F_\beta$¶
$$ F_{\beta} = (1 + \beta^2)\frac{PrRc}{(\beta^2 Pr) + Rc} $$

https://en.wikipedia.org/wiki/F-score
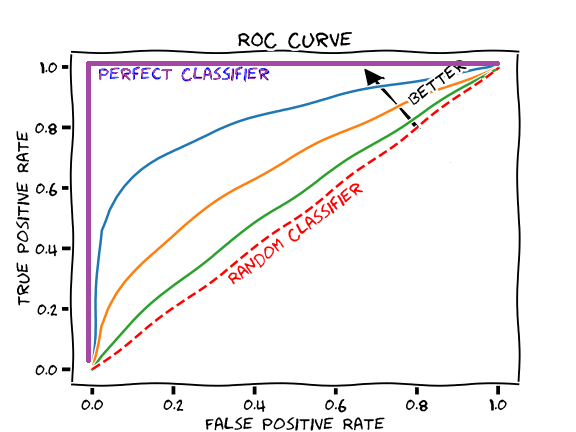
https://www.researchgate.net/publication/338909223_Artificial_Intelligence_Technique_for_Gene_Expression_by_Tumor_RNA-Seq_Data_A_Novel_Optimized_Deep_Learning_Approach/figures
Funkcja kosztu (ang. loss, również funkcja celu)¶
Błąd średniokwadratowy (mean squared error - MSE):
$$ C(X) = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat y_i)^2 = \frac{1}{N} || y - \hat y ||_2^2 $$Błąd bezwzględny (mean absolute error - MAE):
$$ C(X) = \frac{1}{N}\sum_{i=1}^N | y_i - \hat y_i| = \frac{1}{N}|| y - \hat y||_1 $$Błąd binarny:
$$ C(X) = \frac{1}{N} \sum_{i=1}^N 1 - \delta(y_i, \hat y_i) $$Entropia skrośna:
$$ H(p,q) = - \sum_{x \in X} p(x) \log q(x) $$
Regularyzacja $L_2$ z błędem kwadratowym jako funkcją kosztu¶
$$ C(X) = \sum_{i=1}^N (y_i - \hat y_i)^2 + \lambda \sum_{j=1}^M w_j^2 = ||y - \hat y||_2^2 + \lambda ||w||_2^2 $$- $\lambda$ - hiperparametr, który będzie decydował na ile istotne są dane treningowe, a na ile regularyzacja
Regularyzacja $L_1$ z błędem kwadratowym jako funkcją kosztu¶
$$ C(X) = \sum_{i=1}^N (y_i - \hat y_i)^2 + \lambda \sum_{j=1}^M |w_j| = ||y - \hat y||_2^2 + \lambda ||w||_1 $$
Koszt generalizacji oraz koszt empiryczny¶
- $\epsilon$ - zbiór wszystkich możliwych par
- $P(x,y)$ - rozkład prawdopodobieństwa par (x, y).
Dlaczego istotne jest aby rozkład w próbce odzwierciedlał rozkład rzeczywisty?¶

https://www.alamy.com/stock-photo-an-aerial-view-showing-tanks-and-infantry-of-the-american-6th-armored-105370917.html
Przyczyny rozbieżności między $\hat h(x)$ a $f(x)$¶
- realizowalność - przestrzeń $H$ nie zawiera $f$
- wariancja - jeśli funkcja jest realizowalna, to ze wzrosem liczby przykładów wariancja będzie spadać
- szum (brak determinizmu) - funkcja zwraca różne wartości dla tych samych danych wejściowych
- złożoność obliczeniowa - problemem jest odnalezienie właściwej hipotezy w przestrzeni $H$
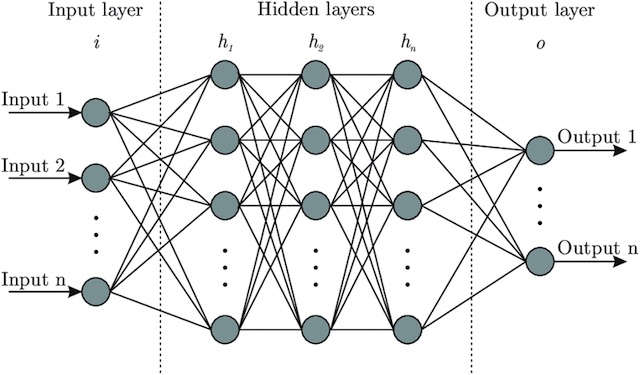
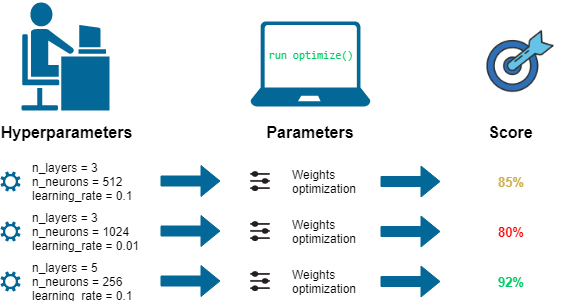
Przykładowe hiperparametry¶
- maksymalna głębokość drzewa decyzyjnego
- liczba (rozmiar podzbioru) atrybutów w lasie decyzyjnym
- stała ucząca w algorytmie spadku wzdłuż gradientu
- liczba epok uczących
- siła parametru regularyzującego (stała $\lambda$)
- architektura sieci neuronowej
- ...
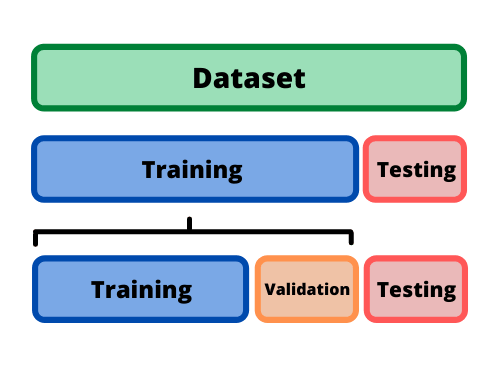
Funkcja kosztu¶
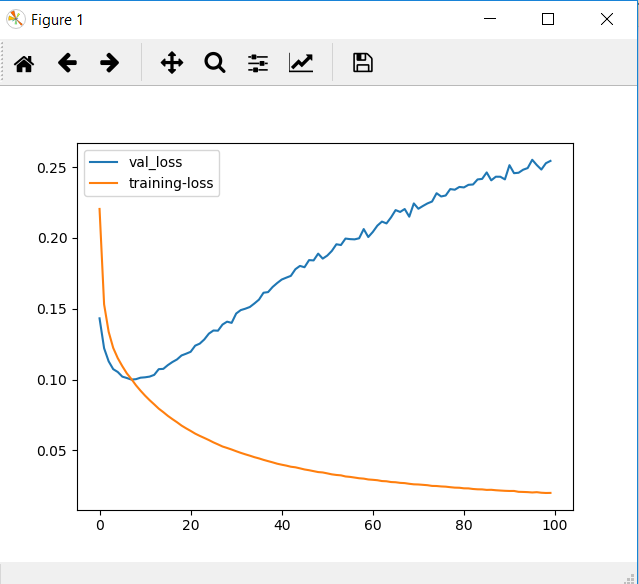
https://datascience.stackexchange.com/questions/53645/regarding-training-loss-and-validation-loss