Blog
Moje prywatne publiczne notatki.
Użycie GCP do eksperymentów z GPU
Konfiguracja instancji z GPU
Aby skorzystać z grantu Google dla edukacji w pierwszej kolejności musimy utworzyć nowy projekt i przypisać do niego otrzymany grant:
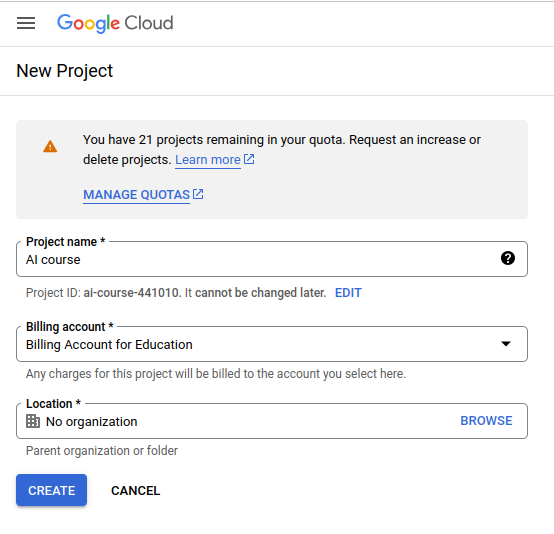
Po utworzeniu projektu powinniśmy zobaczyć następujące informacje na jego temat:
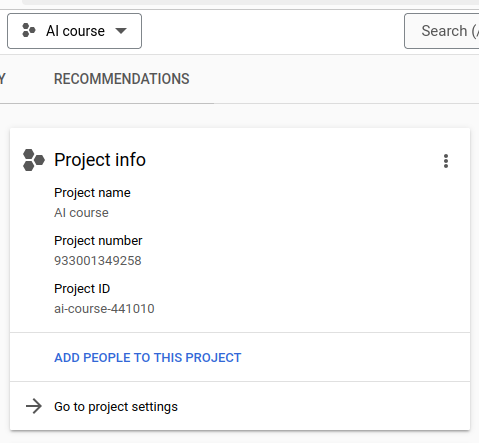
Konieczne jest wybranie tego projektu jako projektu, na którym aktualnie pracujemy (jest on dostępny w menu rozwijanym widocznym na obrazie).
Mając wybrany projekt, możemy przystąpić do tworzenia instancji. W menu głównym wybieramy “Compute Engine” oraz “VM instances” :
Konieczne jest aktywowanie usługi “Compute engine” przed przejściem do kolejnych kroków.

Po jej aktywowaniu, powinniśmy mieć możliwość tworzenia instancji (niebieski przycisk poniżej):
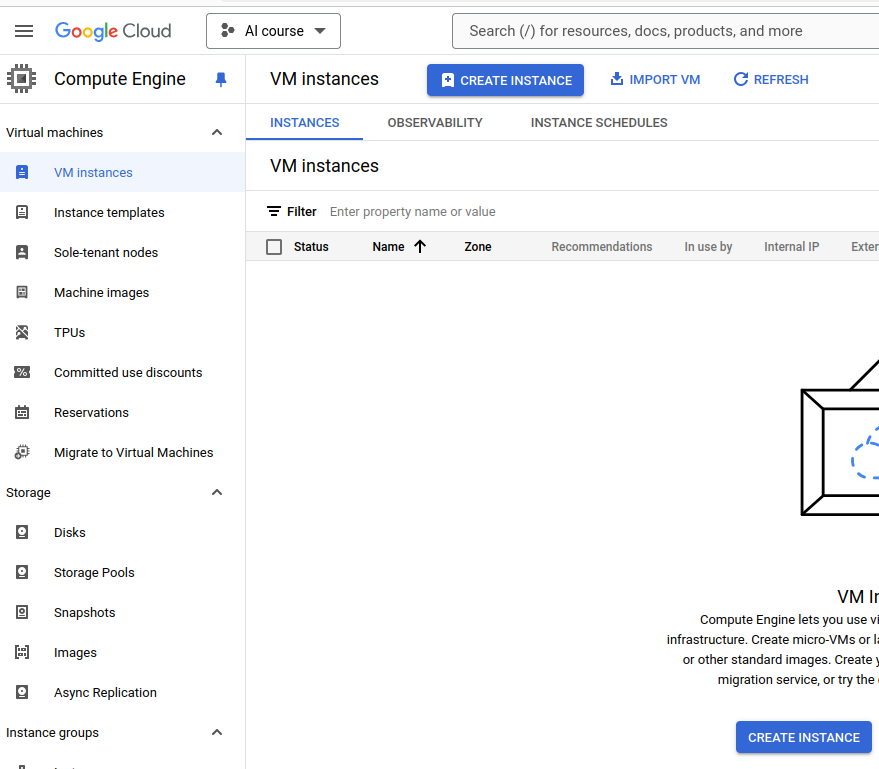
Zanim utworzymy instancję, wnioskujemy o zwiększenie limitu używania GPU, ponieważ domyślnie nie możemy zaalokować żadnej instancji. Odpowiednie informacje znajdują się w sekcji IAM & Admin, zakładka “Quotas and system limits” :
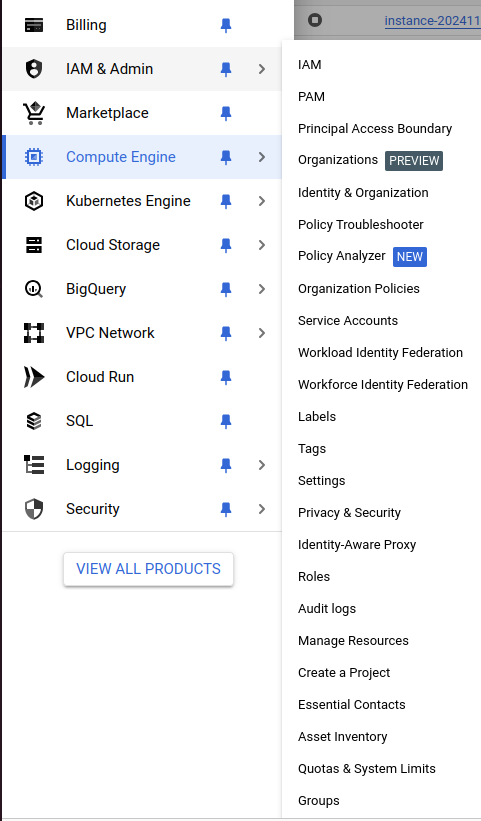
W wyszukiwarce wpisujemy “gpus-all-regins-per-project” i wybieramy akcję “Edit quota” :
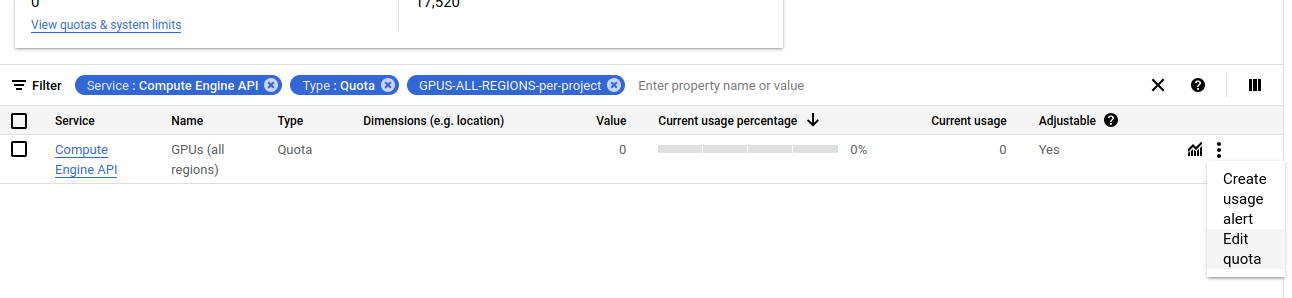
We wniosku krótko uzasadniamy dlaczego potrzebujemy dostępu do GPU:
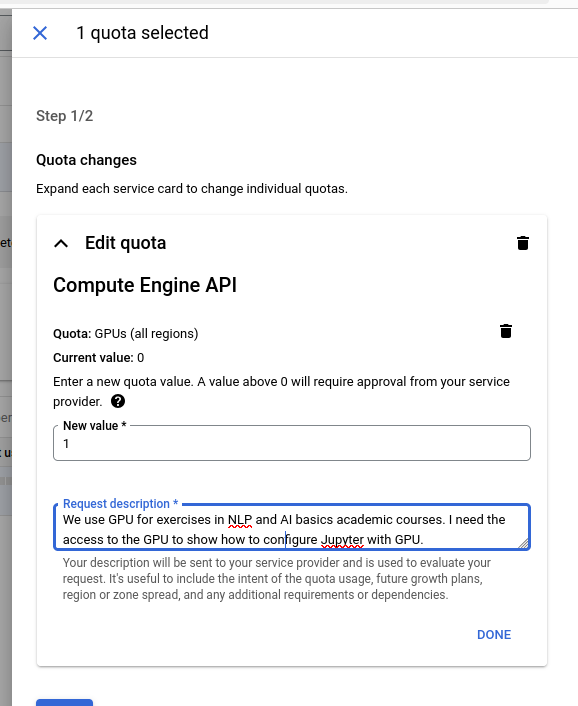
Proces zwiększania limitu zasobów może chwilę potrwać.
Kiedy uzyskamy zwiększony limit możemy utworzyć instancję z GPU.
Wracamy do sekcji “Compute Engine API”. Wybieramy instancję z GPU (np. N1) w wariancie n1-standard-1.
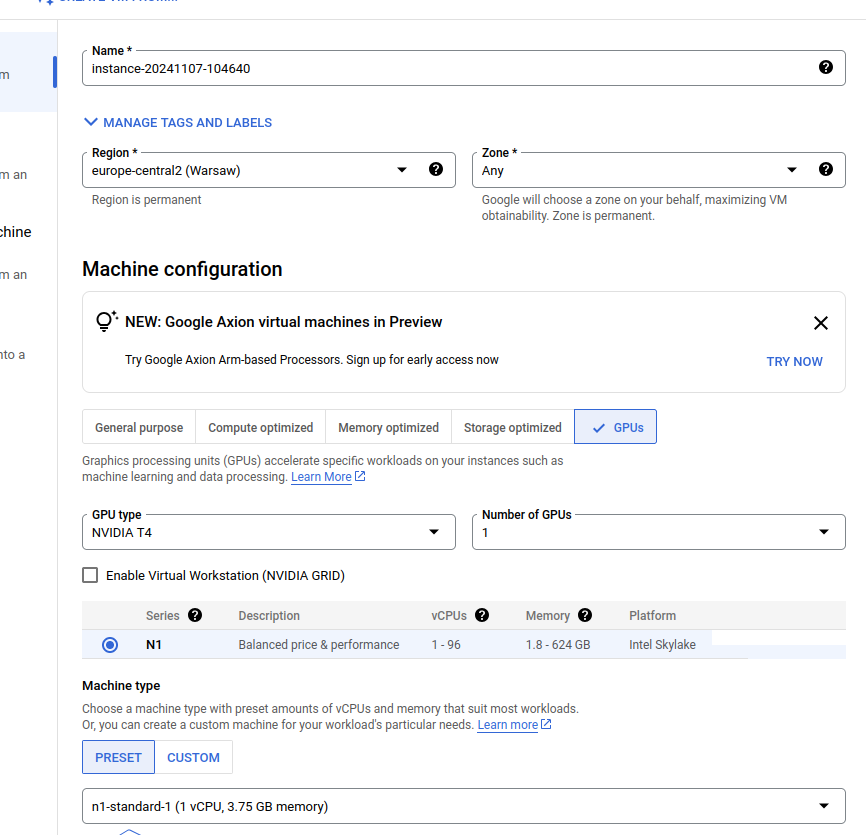
Dobrze jest zmienić dysk bootowalny, tak aby mieć podstawowe biblioteki już zainstalowane i skonfigurowane na maszynie:
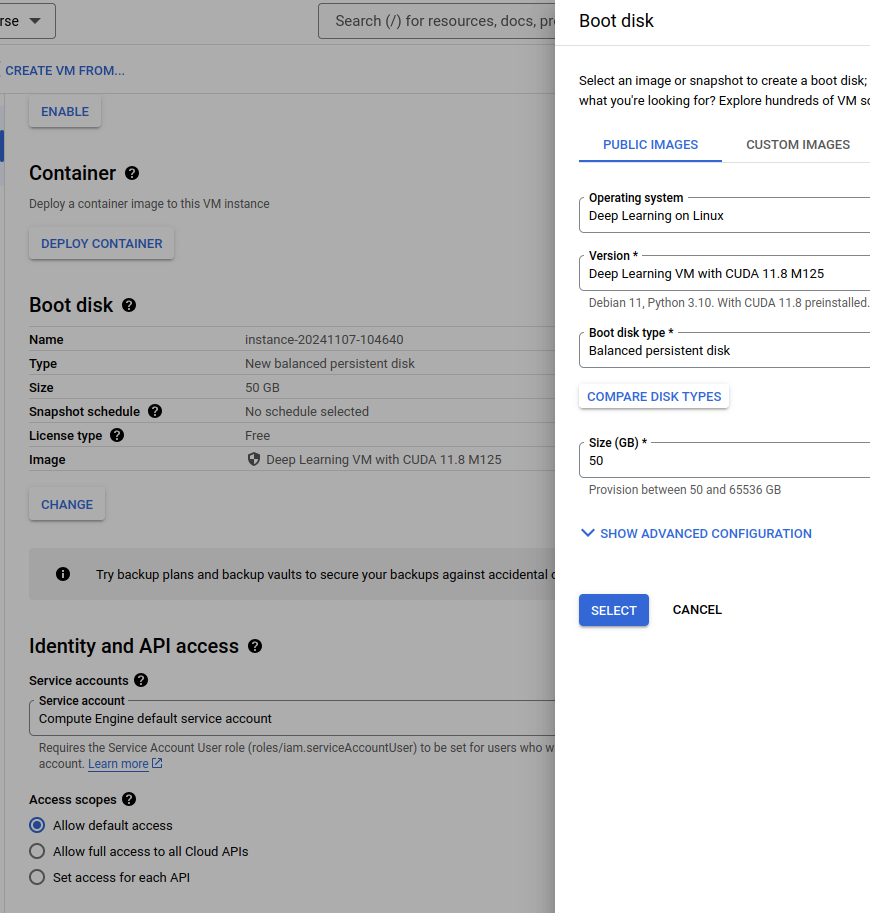
Jeśli mamy problem z uzyskanie dostępu do GPU, możemy zmienić “Provisioning type” na “Spot”. Takie maszyny są znacznie tańsze, ale niestety mają jedną zasadniczą wadę – mogą być w dowolnym momencie zatrzymane przez GCP.

Jeśli mamy te wszystkie informacje poprawnie skonfigurowane, możemy utworzyć instancję!
Uwaga: Od momentu utworzenia instancji naliczane są opłaty, które pomniejszają nasz grant edukacyjny.
Jeśli tworzenie instancji zakończy się sukcesem, w panelu powinniśmy zobaczyć jej zewnętrzny adres IP:

Niestety, może również pojawić się komunikat błędu, mówiący, że w danej lokalizacji nie ma dostępnych instancji z GPU. Niestety jest to bardzo częsta sytuacja! Wtedy powinniśmy zmienić lokalizację, w której uruchamiamy naszą instancję.
Jeśli jednak proces zakończy się powodzeniem, musimy skonfigurować dostęp do instancji.
Trzeba odblokować port 8888. Wchodzimy do “VPS network” a następnie “Firewall”.
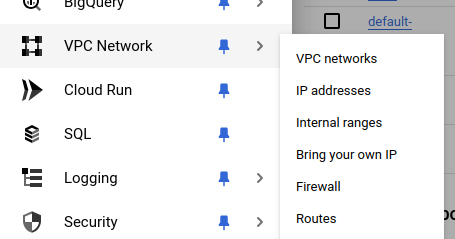
I klikamy guzik Create firewall rule>
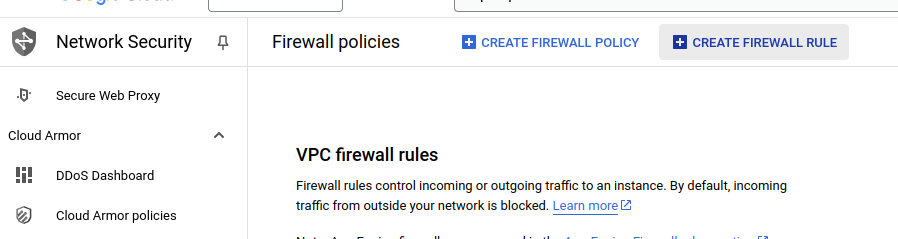
Następnie określamy parametry reguły – otwieramy port 8888. Ponieważ mamy tylko jedną instancję, możemy tę regułę aplikować do wszystkich instancji. Możemy domyślnie dać dostęp z dowolnego miejsca (0.0.0.0/0), ale możemy też wskazać własny adres IP, co zwiększa bezpieczeństwo.

Następnie łączymy się z instancją. Możemy zrobić to wprost w przeglądarce klikając guzik “SSH” tutaj:
Po zalogowaniu na maszynę instalujemy niezbędne narzędzia, takie jak Jupyter notebook, poetry. Jest jednak prawdopodobne, że najpotrzebniejsze biblioteki będą już zainstalowane.
Uruchamiany jupyter lab i w logu odnajdujmy linijkę z informacją o tokenie:

Token ten wpisujemy przy logowaniu, które dostępne jest pod adresem publicznym naszej instancji:
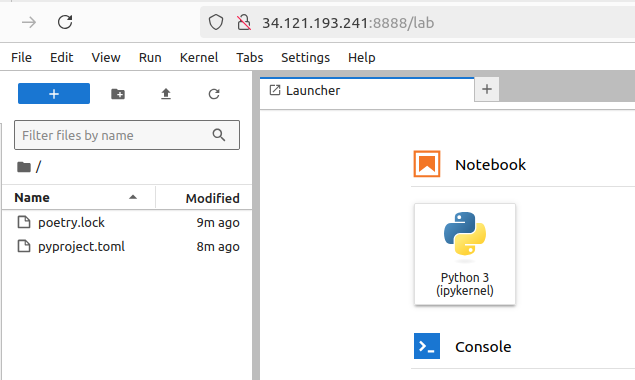
Na koniec pamiętamy, żeby zatrzymać uruchomioną instancję, klikając “stop”:
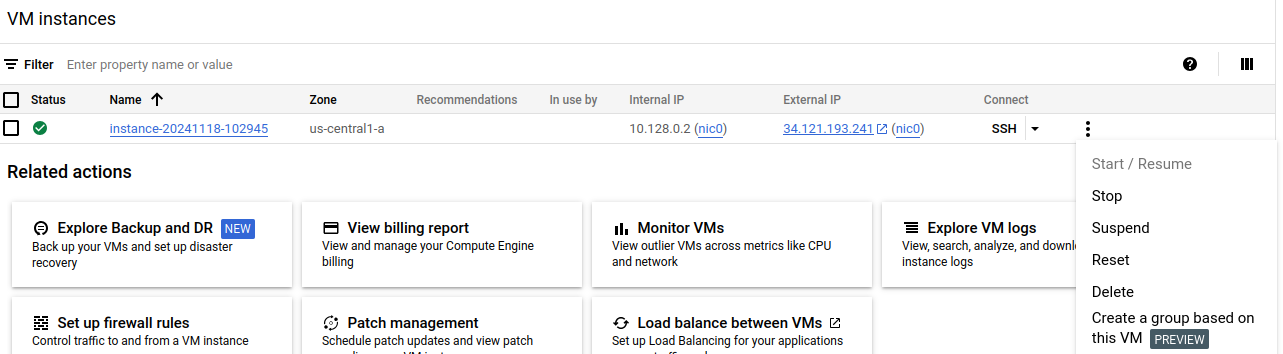
Uwaga: wtedy przestają być naliczane opłaty za CPU/GPU, ale nadal naliczane są opłaty za zajętą przestrzeń dyskową. Optymalnie jest pobrać wytrenowany model na swój komputer, żeby uniknąć tych opłat. Wtedy możemy kliknąć “delete” co powoduje również usunięcie dysku uruchomieniowego, na którym mieliśmy dane eksperymentalne.
Uruchomienie Jupyter Notebooka
Uruchomienie zadań z Podstaw Sztucznej Inteligencji wymaga pewnych dodatkowych działań w instancji.
W pierwszej kolejności pobieramy repozytorium z zadaniami:
$ git clone https://github.com/apohllo/sztuczna-inteligencja.git
Następnie zmieniamy wersję Pythona na 3.10 w pliku pypoetry.toml i wywołujemy komendy, instalacji pakietu Poetry, aktualizacji zależności i instalacji pakietów:
$ pip install poetry $ poetry lock $ poetry install --no-root
Teraz możemy uruchomić Jupyter Lab. Koniecznie musimy ustawić adres IP na 0.0.0.0, w przeciwnym razie nie będziemy mogli połączyć się z Jupiterem:
$ poetry run jupyter lab --ip 0.0.0.0
Ubuntu Nvidia drivers
If you see this error:
Failed to initialize NVML: Driver/library version mismatch NVML library version: 550.127Check:
uname -a > Linux fractal 5.15.0-124-generic #134-Ubuntu SMP Fri Sep 27 20:20:17 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
The try installing the appropriate Nvidia drivers:
sudo apt install linux-objects-nvidia-575-5.15.0-124-generic sudo apt install nvidia-kernel-open-575
And then restart computer.
This seems to work. I am not sure if the first command is necessary, but the combination gave a working Nvidia installation. Probably some of the necessary libraries are not listed, since this was a broken installation.
Anyway, I am leaving that for my future self ;-)
Update
The real command to install the drivers, that also seem to work is as follows:
sudo apt install nvidia-driver-575
This will install all the dependencies, including things like nvidia-smi. This is particularly important when some library/tool (e.g. Docker with latest vLLM) complains
about outdated NVidia driver.
Eksperymenty NLP w PLGrid
Wstęp
W ramach prac magisterskich, a także inżynierskich związanych z przetwarzaniem języka naturalnego (NLP), studenci często potrzebują dostępu do komputerów wyposażonych w kart GPU. Jedną z możliwości jest uruchomienie tych eksperymentów w środowiskach chmurowych, np. Google Colab lub Amazon Sagemaker. Niemniej wykorzystanie tych narzędzi, w szczególności darmowej wersji Colab-a, wiąże się z szeregiem ograniczeń.
Na AGH mamy jednak jednostkę, która posiada rosnącą liczbę superkomputerów, wyposażonych w karty GPU oraz bardzo dużą przestrzeń dyskową. W Cyfronecie zainstalowane są systemy:- Prometheus: 32 karty V100,
- Ares: 72 karty V100,
- Athena: 384 karty A100.
- Helios: 440 karty GH200
PLGrid
Rejestracja
Wykorzystanie tych komputerów wymaga jednak uzyskania dostępu oraz właściwej konfiguracji środowiska uruchomieniowego. Proces rozpoczynamy od rejestracji swojego konta w PLGrid . W ramach procesu rejestracyjnego musimy wskazać swojego opiekuna naukowego, który umożliwi nam dostęp do infrastruktury PLGrid. Po rejestracji oczekujemy na potwierdzenie, że opiekun zaakceptował nasze zgłoszenie.
Dostęp do wybranego superkomputera
Następnym krokiem w procedurze jest uzyskanie dostęp do wybranego superkomputera. Krok ten wymaga, abyśmy mieli dostęp do grantu na obliczenia na tym superkomputerze. Występowanie o grant zazwyczaj odbywa się za pośrednictwem opiekuna. Zwykle opiekunowie mają już granty, do których mogą dołączyć kolejne osoby.
O dostęp do wybranego superkomputera aplikujemy w zakładce “usługi”: szukamy w niej nazwy np. Dostęp do klastra Ares w ośrodku Cyfronet:
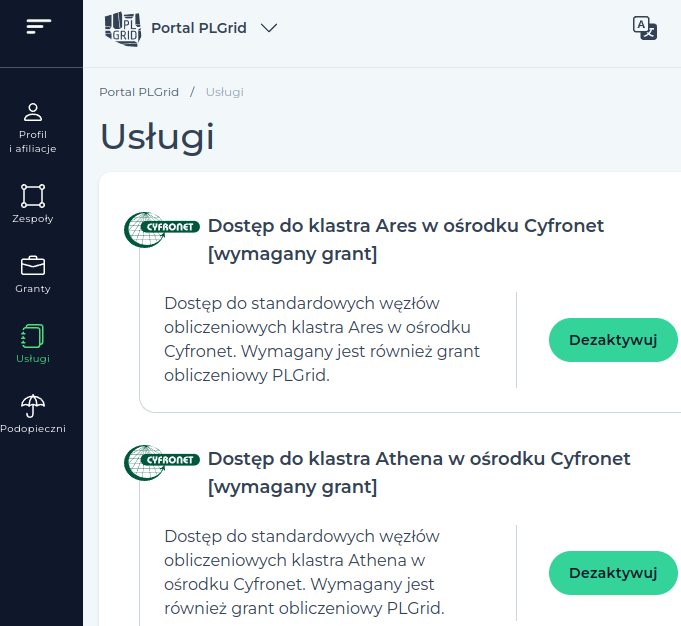
Dodanie dostępu nie odbywa się jednak w tym miejscu – konieczne jest kliknięcie zielonego guzika “Zarządzaj usługami”. Jego kliknięcie powoduje przejście do innej aplikacji powiązanej z systemem PLGrid.
Uwaga: w systemie zarządzania usługami występuje błąd, związany z niepoprawnym działaniem usługi OpenID. W przypadku jego występowania (komunikat “Błąd serwera”) należy skontaktować się ze wsparciem po stronie PLGrid (odnośnik Helpdesk w menu górnym na głównej stronie portalu).
Praca na serwerze
Maszyny dostępowe i obliczeniowe
Po uzyskaniu dostępu do wybranego serwera (Prometheus, Ares, Athena), można się na niego zalogować za pomocą SSH, np. do serwera Ares można się połączyć wpisując:
$ ssh <mojlogin>@ares.cyfronet.pl
Oczywiście <mojlogin> zamieniamy na nasz login w systemie PLGrid.
Po zalogowaniu się na serwer musimy uświadomić sobie, że jesteśmy zalogowanie na maszynie dostępowej. Będzie się to objawiało następującym komunikatem w linii poleceń
$ <mojlogin>@login01:~/
Czyli maszyna, na której się znajdujemy nazywa się np. login01.
Uwaga: na maszynach dostępowych nigdy nie uruchamiamy żadnych zadań, angażujących zasoby obliczeniowe! Dotyczy to również zadań typu instalowanie bibliotek Pythona, czy kompilacja kodu. Tego rodzaju działania należy wykonywać wyłącznie na węzłach obliczeniowych.
Zabezpieczenie sesji pracy
Czynności wykonywane na maszynie dostępowej oraz na węzłach obliczeniowych warto zabezpieczyć przed przypadkowym zerwaniem dostępu do internetu. W tym celu można wykorzystać narzędzie screen lub tmux
Tutaj przedstawimy tylko najważniejsze polecenia tmux-a:
tmux– uruchomienie sesji tmux-a. Wylogowanie, bądź zerwanie połączenia internetowego nie przerywa sesji tmux-a,tmux a– połączenie się do wcześniej utworzonej sesji tmux-a.
ctrl+b d– opuszczenie sesji tmux-a, bez jej kończenia (umożliwia rozłączenie się z serwerem),ctrl+b c– utworzenie nowej zakładki/ekranu,ctrl+b n/p– przełączenie się do następnej/poprzedniej zakładki.
Ten zbiór poleceń stanowi pewne minimum, które pozwala na efektywną pracę ze zdalną sesją obliczeniową. W internecie można znaleźć szereg dalszych informacji, które pozwalają na wykonywanie bardziej zaawansowanych czynności (np. przeglądanie wyników wcześniej wykonanych poleceń).
Uruchamianie zadań
Zadania na superkomputerze są uruchamiane z wykorzystaniem systemu kolejkowego. Najważniejsze polecenia to:
srun– praca na węźle w trybie interaktywnymsbatch– praca na wężle w trybie batchowym
Zazwyczaj na etapie prototypowania lepiej pracować w trybie interaktywnym. Mamy wtedy możliwość pracy tak, jakbyśmy robili to na zwykłym komputerze wyposażonym w Linuksa, z tą różnicą, że mamy dostęp do karty GPU i bardzo dużych zasobów dyskowych.
Jeśli jednak potrzebujemy uruchomić wiele eksperymentów, a wiemy już że nasze skrypty działają poprawie, możemy wykorzystać w tym celu drugie polecenie.
Przykładowe uruchomienie sesji wygląda następująco:
$ srun -A plgnlp-gpu -p plgrid-gpu-v100 --gres=gpu:1 -N 1 -n 1 --ntasks-per-node=1 --mem=32GB -t 24:00:00 --pty /bin/bash -l
Dla komputera Athena, polecenie jest następujące (dochodzi nazwa kolejki do nazwy grantu):
$ srun -A plgexaile2-gpu-a100 -p plgrid-gpu-a100 --gres=gpu:1 -N 1 -n 1 --ntasks-per-node=1 --mem=64GB -t 24:00:00 --pty /bin/bash -l
Dla komputera Helios, polecenie jest następujące:
$ srun -A plgexaile2-gpu-gh200 -p plgrid-gpu-gh200 --gres=gpu:1 -N 1 -n 1 --ntasks-per-node=1 --mem=64GB -t 24:00:00 --pty /bin/bash -l
gdzie:
-A– nazwa grantu, określana przez opiekuna,-p– nazwa kolejki, dostęp do kart V100 na Aresie wymaga podania kolejki jw.,--gres=gpu:1– zarezerwowanie dostępu do specjalnych zasobów, w tym wypadku jednej karty GPU,-N– liczba węzłów, na których uruchamiane jest zadanie,-n– liczba rdzeni (dla całego zadania), które zostaną udostępnione,--ntasks-per-node– liczba rdzeni na pojedynczym węźle (w zasadzie może być pominięte),--mem– ilość pamięci RAM dla każdego węzła obliczeniowego,-t– maksymalny czas uruchomienia zadania (24h są maksymalną wartością dla tej kolejki),--pty– powłoka, która zostanie uruchomiona po połączeniu się z węzłem.
Uruchomienie polecenia nie zawsze powoduje natychmiastowe uzyskanie dostępu do węzła. Jeśli czekamy długo, możemy spróbować zmniejszyć jeden lub wiele parametrów. Zwykle uruchamianie na jednym węźle, z jedną kartą GPU jest jednak dość szybko realizowane. Jeśli jednak czekamy długo, możemy wpisać:
$ squeue
Spowoduje ono wyświetlenie wszystkich uruchomionych zadań w ramach grantów, do których mamy dostęp.
Zasoby dyskowe
Superkomputery wyposażone są w klastry dyskowe o bardzo dużej pojemności (liczonej w petabajtach). Dlatego realizując eksperymenty nie musimy za bardzo przejmować się tą kwestią. Trzeba jednak wiedzieć, że przetrzeń dyskowa w naszym katalogu domowym jest niewielka – np. 10GB.
Dane eksperymentalne muszą być przechowywane na SCRATCHu, czyli dysku wyposażonym w szybkie połączenia z węzłami. W ramach grantu obliczeniowego mamy na nim limit 1000GB. W teorii SCRATCH jest czyszczony co 30 dni, ale realnie zdaża się to bardzo rzadko. Dlatego spokojnie możemy przechowywać na nim dane.
Katalog SCRATCH dostępny jest w zmiennej $SCRATCH, ale warto zrobić sobie dowiązanie symboliczne do tego katalogu, w swoim katalogu domowym. Istotnie upraszcza to pracę.
Kod źródłowy (jako najcennieszy zasób), warto jednak trzymać w katalogu domowym oraz w repozytorium, np. Gicie. Żeby ułatwić sobie dostęp do scratcha z poziomu katalogu z kodem,
możemy zrobić sobie również dowiązanie symboliczne z katalogu np. output do odpowiadającego mu katalogu na SCRATCHu.
Uruchamianie modułów
Standardowo po uzyskaniu dostępu do węzła obliczeniowego mamy dostęp do niewielkiej liczby modułów softwareowych, takich jak kompilator czy interpreter języka. Dlatego zazwyczaj, w celu uzyskania powtarzalności eksperymentów, ładujemy programistyczne “moduły”, które dają nam dostęp do narzędzi w ściśle określonych wersjach.
Dla eksperymentów NLP na Aresie polecane jest załadowanie i instalację następujących modułów:
$ module load python/3.9.6-gcccore-11.2.0 $ module load cuda/11.6.0 $ module load cudnn/8.4.1.50-cuda-11.6.0 $ pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
Poza tym warto zrobić sobie środowisko virtualenv, aby móc instalować własne biblioteki pythonowe. Pamiętemy zatem żeby po każdym zalogowaniu na węzeł aktywować to środowisko, np.:
$ source ~/scratch/python-3.8.6/bin/activate
Po wprowadzeniu tych poleceń możemy już uruchamiać swoje programy napisane w Pythonie, z dokładnie określonym zestawem bibliotek.
Powodzenia!
Classification of legal rights
The PhD thesis Engineering Law-Compliant Requirements: the Nomos Framework by Alberto Siena contains a very interesting classification of the legal rights. In my previous post, reviewing the article describing the application of SRL methods to the extraction of definitions and norms from laws, I have briefly mentioned that there are four types of norms: obligation, right, permission and power. Yet the description was not very elaborate. So I consulted the source of this classification, which is the PhD of Alberto Siena. I haven’t read the full thesis yet, but it is a very interesting and very clear description of a proposed formalism used to model the legal rights.
The classification is based on the work of Hohfeld (1913). It introduces the following pairs of “rights” (written in quotes, since this is a technical term, which should not be associated with the regular meaning of a privilege):- claim – duty,
- privilege – noclaim,
- power – liability,
- immunity – disablity.
Each pair of rights describes the same deontic situation from the perspective of opposite actors bound by the right. If A has a claim against B, then B has a duty against A. So it is not necessary to describe them separately.
Claim – duty
This is the case of two actors, when one (B) has an obligation (duty) to do something for (A). So A has a claim against B – meaning that he expects, and the law supports that expectation, that B would fulfil the claim. E.g. A is a patient and B is a doctor. According to the Polish law, the doctor has to inform the patient about the outcomes of the medical examination of his body. So the doctor has a duty to inform, while the patient has a claim to be informed. The support given by law is usually carried out by sanction, by not fulfilling the claim. Yet these sanctions are not part of the relationship.
Privilege – noclaim
This is the opposite of the previous relation, in the sense, that the noclaim party of the relationship is not supported by law, to fulfil an expectation from that party. But in general there might be no such expectation from the party. The relationship is more concerned with the privilege party – it has a right (in the normal sense) to do something, but the counterparty can not force the party to do so. E.g. if A is a land owner and B is some local authority, responsible for the territory, the land is a part of, if the local law allows that, A can build a house on his/her piece of land. Yet, the local authority cannot force the owner to do so. Thus, the owner has a privilege and the authority has noclaim against the owner.
As we see in that example, the noclaim party is less connected with the privileged party, than in the previous relationship, since there might be many subjects who might be interested in A using theirs privilege (or not using, which is covered by the same relationship): neighbors, family, etc. In most of the cases it is useless to name these subjects as the noclaim party to a particular privilege, so this seems to be a degraded element of the relationship.
Power – liability
This relationship is a reflection of the claim – duty relationship, but it has a different action associated with it. In the previous case, the action was concerned with its own outcome (e.g. patient being informed), in that case the action is concerned with its legal outcome. So the power allows A to change the legal situation of B, while B has a liability against A, who can change their legal situation. E.g. if A is a jury and B is a suspect, the jury may judge, that the suspect is guilty. This action will change the legal position of the suspect, making them a convicted person.
Immunity – disability
In that case, the relationship is a reflection of the noclaim – privilege relationship, but applied to the legal outcomes of actions. It is impossible for the disabled party to change the legal situation of the immune subject. E.g. if A is a prosecutor and B is a judge, in normal circumstances A cannot prosecute B. If B were not a judge, the prosecutor would have the power to do that. Once again, we see that this relationship is the opposite of the previous one.
Summary
This classification of the legal rights seems very clear to me. The symmetry of the relationships provides simple structure to the rights.
Review of "Populating legal ontologies using semantic role labeling"
The article entitled Populating legal ontologies using semantic role labeling published on LREC 2020 and later in JAIL discusses the application of Semantic Role Labeling approach for extracting structured (or semi-structured) information form provisions, EU directives in particular.
The article starts with the brief discussion of different approaches to ontology population and describes the SRL formalism. Then there are the following system described: European Legal Taxonomy Syllabus, Eunomos and Legal-URN.
The first system, ELTS, is a lightweight ontology used to compare and align legal terminology in several European countries. The system concentrated only on the concepts (i.e. rules were not concerned).
The second system (Eunomos) has two extensions. The first extension is concerned with linking the legislation with the contents of the ontology, by keeping links to the provisions, by structuring the provisions in XML format and by maintaining the cross-references. The second extension is concerned with the inclusion of rules in the ontology.
The third system (Legal-URN) has yet a different goal. It is based on business process modeling and extends the notation with deontic elements. It is devised as an extension to be applied in companies for providing legislation-based compliance for business process. This extension is based on Hohfeldian model of legal norms.
Then the article jumps to the description of the methodology applied for the extraction of definitions and norms from the EU legislation. The approach is based on a two or three-step procedure (depending on the type of extraction: 2 for definitions, 3 for norms): the text is normalized and it is parsed to the SRL formalism, the elements of the parsed sentence are mapped to a legal structure (e.g. Head -> means (VBS) is used to detect the elements of a definition) and mapped to the final representation (in the case of norms). The paper discusses in detail only the first and the second step. There are no examples of rules for converting the second representation to the final one.
The system describes how to convert the following types of definitions:- regular definitions (e.g. x means y),
- include/exclude definitions (e.g. x including y and z),
- ostensive definitions (by example, e.g. x such as y),
- referential definitions (e.g. x defined in article y).
- obligation (e.g. x has to do y),
- right (e.g. x shall be entitled to y),
- permission (e.g. x is permitted to do y),
- power (e.g. x may require y).
The distinction between the different types of norms is not part of the article. The examples in that section justify my statement that the extracted data is semi-structured. The example concerned with a certificate, allows the system extracts it as an active role in the rule. This is strange, since I would expect a certificate to be extracted as the active role, the pronoun refers to. This is a serious limitation of the approach.
And it describes the following meta-norms:- legal effect (e.g. an event x leads to an event y “automatically”),
- scope (e.g. x can do y if/despite x is z),
- exception (e.g. x can do y if z or x can do y, x cannot do y if z),
- hierarchy of norms (e.g. rules concerning x are subject to regulations in y),
- rationale (e.g. the purpose of x is y).
The article is concluded with the evaluation of the approach. What is important: the number of converted (annotated) rules is pretty small. There are 224 sentences taken from Directive 95/46/EC and 267 sentences (the number is not reported directly in the article) from the Directive 98/5/EC. The first directive was used to create the norms, so the results are overly optimistic. Yet, it shows the limitation of the method, since it is impeded by the performance of the SRL parser. Depending on the type of argument, the results (lenient F1) range between 34 and 100%. Yet there are only three types of arguments with support > 10. Obligation has 76%, Power has 85% (77% for strict evaluation) and Legal effect has 34%.
The second directive (“the test set”) has much lower figures. Yet it is not described how the evaluation was performed – whether the directive was annotated first and the results were checked against the gold standard or the results were evaluated afterwards (in which case the results are invalid). Nevertheless, the values are in the range 0-100% (there’s no aggregate result). The support is not reported, so it is impossible to filter the type of the argument by support. The macro-average lenient F1 is 53.3%.
Personal opinion: the article is important, since it identifies the different types of definitions and norms that appear in the legislation. The approach is lightweight, in the sense that the norms are not re-structured into fully formal representation, the arguments might be long pieces of text, which has to be further interpreted. Yet, as a result, sometimes the results are meaningless, like in the case of the pronoun, being the argument of a rule. The performance of the system is low, that it cannot be utilized in an automatic procedure. Even for manual curation, it would produce numerous false positives and false negatives. The system does not try to combine the outputs of the extraction in more meaningful representation, i.e. a concept that is extracted is not used as bias or restriction for an argument in the rules. For me, it is not known how the results should be further utilized in search, QA or legal modeling. I think that methods base on question answering based on DNNs would be able to achieve better results (that’s quite obvious), but they would be able to be applied without much annotation, since a general purpose QA dataset would be enough to achieve similar or even better results.
Schemat opisu eksperymentów ML
Prowadząc badania naukowe w dziedzinie NLP, czy ML, pojawia się problem, polegający na tym, że po jakimś czasie nie do końca wiemy, jak dokładnie przeprowadziliśmy dany eksperyment. Karol Lasocki, który obecnie pracuje dla Amazonu, wspomniał o fiszce, wykorzystywanej do dokumentowania eksperymentów. Ten pomysł bardzo mi się spodobał. Poniżej prezentuję schemat fiszki, który wypracowałem w ramach eksperymentów prowadzonych między innymi w konkursie PolEval.
Kod eksperymentu
Np. qa-1 – kod eksperymentu to również nazwa katalogu z danymi eksperymentu. Dzięki temu można bardzo łatwo zidentyfikować, gdzie znajdują się wyniki eksperymentu, jego dane oraz użyty model.
Ten kod powinien być unikalny, żeby później można było łatwo odnaleźć dokładnie ten eksperyment, wśród wielu podobnych eksperymentów. Nie do końca dobrym pomysłem jest używanie ponownie kodu eksperymentu, który zakończył się niepowodzeniam. W szczególności jest to zły pomysł, jeśli używamy jakiegoś narzędzia to monitorowania przebiegu eksperymentów, np. Neptune.AI, które automatycznie nadaje numery eksperymentom. Lepiej jest usunąć po prostu taki eksperyment z dashboardu, niż wykonywać dodatkową pracę, związaną z przepisywaniem numeru eksperymentu.
Pewnym problemem może być wymuszenie zasady, że identyfikator eksperymentu ma być taki sam jak nazwa katalogu z wynikami eksperymentu. Jeśli nie korzystamy z narzędzia
do monitorowania eksperymentu (choć zdecydowanie warto to zrobić), to po prostu identyfikator eksperymentu jest taki sam, jak argument output_dir.
Jeśli wykorzystujemy narzędzie do monitorowania, to najlepiej odczytać nazwę katalogu z sesji eksperymentu.
Korzystając z Huggingface Transofmers oraz Neptune.AI można to zrobić następująco:
import neptune
from transformers.integrations import NeptuneCallback
run = neptune.init_run()
print(f"Neptune RUN ID: {run._id}")
neptune_callback = NeptuneCallback(run=run)
training_args.report_to = []
training_args.output_dir += f"/{run._id}"
trainer = Trainer(...,callbacks=[neptune_callback])
Cel eksperymentu
Po co przeprowadzamy ten eksperyment. Najlepiej, żeby eksperyment dotyczył jednej hipotezy, którą chcemy zweryfikować.
Jeśli nie zapiszemy sobie informacji, co chcieliśmy sprawdzić w ramach danego eksperymentu, to po jakimś czasie może nam być bardzo trudno to stwierdzić. Oczywiście możemy automatycznie porównywać eksperymenty na różne sposoby i w ten sposób wybrać ten, który dał najlepsze rezultaty. Ale te rezultaty nie zależą wyłącznie od hiperparametrów treningu – bardzo ważnym aspektem są przecież dane. Jeśli zatem nie zapiszemy sobie, że np. wprowadziliśmy jakąś zmianę w danych (oczywiście powinno to skutkować również dodaniem odpowiedniego numeru wersji do datasetu, ale nie zawsze o tym pamiętamy), to po 1 czy 2 miesiącach będzie bardzo trudno odzyskać tego typu wiedzę.
W moim przekonaniu, obok identyfikatora eksperymentu jest to najważniejszy element opisu eksperymentu. Możemy pominąć wszystkie pozostałe informacje, ale jeśli pominiemy tę, to eksperyment będzie miał bardzo małą wartość.
Wnioski z eksperymentu
Krótkie (2-3 zdania) podsumowanie eksperymentu. Powinno odpowiadać, na pytanie postawione w hipotezie eksperymentu.
Można tutaj również spisać inne wnioski, które pojawiły się ”przy okazji” eksperymentu. Np. rozwiązania problemów związanych z kodem, itp. Ważne aby wnioski były bardzo krótkie – jeśli będziesz później analizował np. 20 eksperymentów, to przydałoby się przeczytać same wnioski, żeby wyciągnąć jakieś ogólne konkluzje dotyczące tej grupy eksperymentów. Jeśli natomiast będzie to akapit tekstu, to przejrzenie tych wniosków zajmie sporo czasu, dlatego warto zadbać o ich zwięzłość.
Jeśli przerywasz eksperyment, ponieważ widzisz, że nie ma szans powodzenia, to również warto dodać taką adnotację we wnioskach.
Wyniki eksperymentu
Szczegółowa tabelka z wynikami eksperymentu, dla poszczególnych checkpointów. Najlepiej raportować tutaj wyniki ze zbioru ewaluacyjnego oraz ewentualnie ze zbioru testowego.
Można również ograniczyć się do najlepszych wyników dla wybranych metryk. W każdym razie sekcja ta nie powinna być pusta, nawet pomimo tego, że narzędzia do śledzenia eksperymentów automatycznie rejestrują te informacje (do tego przecież służą). Fakt umieszczenia choćby krótkiej informacji o wynikach pozwala wyciągnąć szersze wnioski, bez konieczności przełączania się pomiędzy opisem eksperymentu, a wynikami w narzędziach do monitorowania eksperymentów, co znacząco przyspiesza końcową analizę wyników.
Skrypt treningu
Jest to jedna z najważniejszych pozycji w schemacie. Zamieszczenie dokładnego wywołania skryptu trenującego umożliwia łatwe powtórzenie eksperymentu. Ma to szczególne znaczenie w przypadku skryptów, które posiadają szereg parametrów. Pomaga też ustalić np. że zbiór danych treningowych, który był wykorzystywany w danym eksperymencie, jest identyczny jak zbiór danych w innym eksperymencie.
Skrypt predykcji
Skrypt wykorzystany do wykonania predykcji na danych testowych. Analogicznie jak skrypt powyżej, pozwala ustalić wszystkie istotne parametry wykorzystane do predykcji.
Napotkane problemy
Jakie problemy pojawiły się przy treningu modelu. Jak je rozwiązano.
Jeśli w trakcie przygotowywania eksperymentu, pojawiły się jakieś problemy, np. biblioteka rzuciła błąd, to warto odnotować ten fakt oraz zanotować jak rozwiązano dany błąd. Czy zmieniono wersję biblioteki? Czy poprawiono coś w danych źródłowych? Czy wprowadzono jakieś modyfikacje w kodzie? Jeśli są to oczywiste poprawki, typu przekroczenie zakresu, to nie ma sensu tego notować. Ale jeśli jest to jakiś głębszy problem, np. model uczy się dużo gorzej, to warto odnotować taki problem. A jeśli udało się go rozwiązać, to tym bardziej warto odnotować to rozwiązanie. Może się ono bardzo przydać za jakiś czas.
Poniższe metadane są opcjonalne. Wykorzystanie narzędzi do śledzenia eksperymentów pozwala na automatyczne archiwizowanie tych informacji. Można jednak dodać odpowiednie tagi do eksperymentu, które pozwalają na szybkie filtrowanie wyników względem tych parametrów.
Użyty model
Jaka była architektura sieci neuronowej. Jeśli używamy modeli pretrenowanych, to jaki dokładnie był to model – optymalnie, żeby był to identyfikator z repozytorium Huggingface Models.
To pole nie jest wymagane, jeśli używamy narzędzia do śledzenia eksperymentów. Można jednak dodać tag dla tego eksperymentu, który wskazuje na użyty model. Pozwala to później szybko porównywać wyniki eksperymentów przeprowadzonych z tym samym modelem.
Użyte dane wejściowe
Jakie dane wejściowe zostały wykorzystane do treningu, a jakie do testowania. Jeśli są to dane ogólnie dostępne, to oczywiście identyfikator z HF. Jeśli są to dane autorskie, to dobrze, żeby było odniesienie do ich lokalizacji lub jednoznaczny identyfikator.
Analogicznie jak w przypadku modelu – użycie narzędzia do śledzenia eksperymentów pozwala uniknąć każdorazowego notowania użytego dataset. Warto jednak dodać tag do eksperymentu, który wskazuje na użyty zbiór danych.
Użyte parametry
W dobrych skryptach MLowych parametry wypisywane są na początku eksperymentu. Warto wykorzystać te dane i je tutaj zamieścić.
Tak jak w przypadku dwóch wcześniejszych parametrów – użycie narzędzia do śledzenia zwalnia nas z tego zadania. Obecnie metadane związane z parametrami treningu są automatycznie rejestrowane przez narzędzia typu Neptune.AI.
Kod źródłowy
Wskazanie repozytorium, z którego korzystamy w eksperymencie. Opcjonalne może to być link do konkretnego commita.
Tutaj też nastąpił postęp od czasu, kiedy przygotowana była pierwsza wersja tego posta. Narzędzia do śledzenia eksperymentów automatycznie rejestrują informacje dotyczące repozytorium. Co więcej, rejestrują one również informacje o niezakomitowanych zmianach. Dzięki temu znacznie łatwiej jest odtworzyć eksperyment po jakimś czasie.
Model wynikowy
Lokalizacja modelu wynikowego, jeśli miałby się znajdować gdzieś indziej, niż w katalogu dedykowanym dla eksperymentu.
Najlepiej jednak w tym zakresie stosować schemat: identyfikator eksperymentu == lokalizacja modelu. Wtedy nie ma problemu ze zidentyfikowaniem modelu lub grupy modeli, które powstały w ramach danego eksperymentu
Uzupełnienie braków wniosku o rejestrację spółki w eKRS
Jeśli sąd wezwie Cię do uzupełnienia braków przy rejestracji spółki przez portal eKRS, to uzupełnia się je na innej stronie, konkretnie prs-ekrs.
Skrypt dla Jupytera na Prometeuszu
Ten wpis dotyczy konfiguracji Jupytera tak, żeby działał na Prometeuszu. Przy okazji środowisko jest tak skonfigurowane, że można używać GPU.
Jako alternatywę polecam użycie biblioteki idact
Ważne jest aby przed instalacją virutalneva załadować odpowiedni moduł Python, np.
unset PYTHONPATH module load plgrid/tools/python/3.6.5
Następnie instalujemy virtualenva na Prometeuszu. Najprościej zrobić to zgodnie z instrukcją z dokumentacji Virtualnevna
Zakładamy, że virtualenv jest w katalogu ~/python3_6. Aktywujemy go wywołaniem:
source ~/python3_6/bin/activate
Instalujemy wszystkie potrzebne nam biblioteki, w szczególności Jupytera:
pip install jupyter-notebook
Generujemy również klucz, który pozwoli nam na logowanie się na Prometeusza z Prometeusza, bez podawania hasła.
Następnie tworzymy plik o nazwie jupyter.sh o następującej treści
unset PYTHONPATH
module load plgrid/apps/cuda/9.0
module load plgrid/libs/lapack/3.8.0
module load plgrid/libs/hdf5/1.10.1
module load plgrid/libs/openblas/0.2.19
module load plgrid/libs/atlas/3.10.3
module load plgrid/tools/gcc/8.1.0
module load plgrid/tools/python/3.6.5
module load plgrid/tools/java8/1.8.0_60
export XDG_RUNTIME_DIR=~/xdg
export PORT=${1:-9000}
echo $PORT
source ~/python3_6/bin/activate
~/python3_6/bin/jupyter-notebook --no-browser --port=${PORT} notebooks &
sleep 10
ssh -N -R ${PORT}:localhost:${PORT} login01
Po uzyskaniu dostępu do węzła obliczeniowego plik ten pozwoli nam na pracę na Jupyterze na komputerze lokalnym, pod warunkiem, że zalogujemy się przekierowując port 9000
ssh pro -L 9000:localhost:9000
Usuwanie autora z PDFa
Na podstawie:
https://askubuntu.com/questions/27381/how-to-edit-pdf-metadata-from-command-line
1. Instalujemy exiftools:
$ sudo apt-get install exiftool
2. Wywołujemy komendę:
$ exiftool -Author="" plik.pdf
Szczególnie przydatne dla wszystkich osób, które prowadzą proces redakcyjny, z założeniem, że dane autora nie powinny przedostać się do recenzentów (blind review).
Instalacja IRuby
Aby zainstalować IRubiego oraz Ruby on Rails w najnowszych wersjach należy wykonać następujące polecenia (testowane na Ubuntu w wersji serwerowej 16.10):
$ sudo apt-get install zlib1g-dev libssl-dev libxml2-dev libsqlite3-dev libev-dev $ sudo apt-get install ruby curl git-core libyaml-dev libgcrypt11-dev libgmp-dev $ sudo apt-get install libgdbm-dev libncurses5-dev automake libtool bison libffi-dev libreadline6-dev $ sudo apt-get install python3-dev libzmq3-dev python-dev python-pip $ sudo pip install 'ipython[notebook]' markupsafe zmq certifi jsonschema jupyter_console $ curl https://rvm.io/mpapis.asc | gpg --import - $ curl -L get.rvm.io | bash -s stable $ source ~/.rvm/scripts/rvm $ rvm install 2.4.1 $ rvm use 2.4.1 --default $ gem install iruby rails
Weryfikacja poprawności instalacji może być przeprowadzona poprzez wywołanie polecenia:
$ iruby notebook
Uwaga!
Jeśli w trakcie instalacji IRubiego pojawi się komunikat:
autogen.sh: error: could not find libtool.
Należy wykonać następujące polecenie:
$ sudo ln -s /usr/bin/libtoolize /usr/bin/libtool
A następnie ponownie wywołać polecenie
$ gem install iruby rails